万倍加速——高性能正态积分的终极方案附代码
在毫秒必争的衍生品定价与大规模风险回测中,传统的正态分布积分运算往往是代码毒瘤和性能瓶颈。本文将介绍一种完全向量化的数值算法,助你利用现代 CPU、GPU 甚至TPU 的并行能力突破卡点。

在毫秒必争的衍生品定价与大规模风险回测中,传统的正态分布积分运算往往是代码毒瘤和性能瓶颈。本文将介绍一种完全向量化的数值算法,助你利用现代 CPU、GPU 甚至TPU 的并行能力突破卡点。
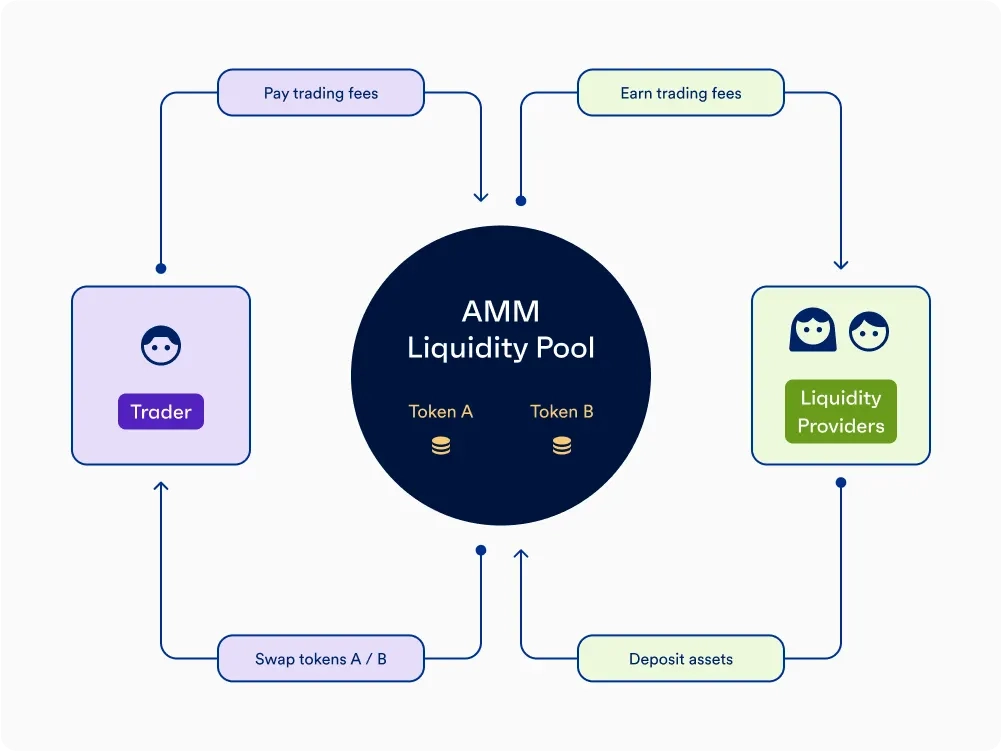
许多人将链上交易所(DEX)如Uniswap 的流动性提供(LP)视为一种被动的“理财”或“挖矿”行为,但这是一种极其危险的误解。从市场微观结构来看,AMM 本质上是一个 由算法定义的逆向选择(Adverse Selection)博弈场。
本文是【AMM 量化深潜】系列的第一篇。我们将摒弃传统的散户视角,从宏观市场均衡出发,通过严谨的数学推导剥离“无常损失(IL)”的伪装,引出专业视角下真正的 AMM 做市核心风险度量——再平衡损失(Loss-Versus-Rebalancing, LVR)。
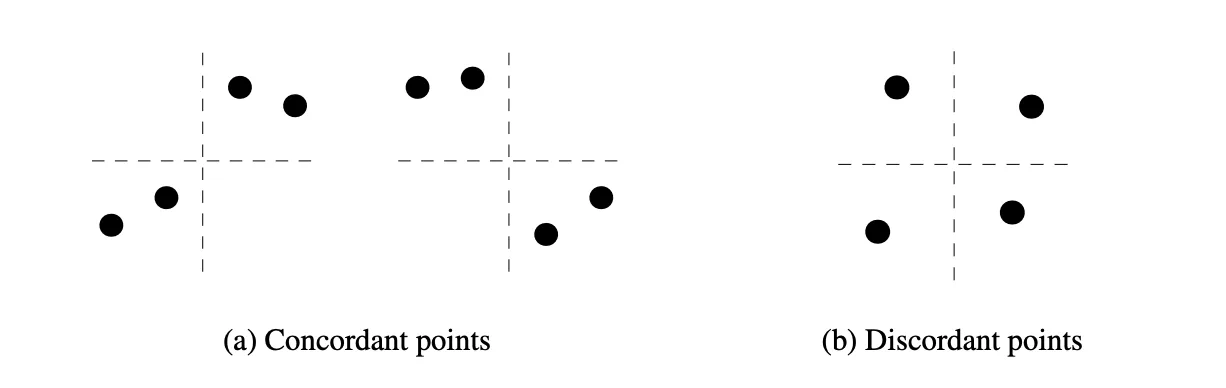
在前文 《衡量序列相关性的三个指标》 中我们介绍了能够发现变量间非线性、非单调关联的Chatterjee相关系数。它形式简单,计算快速,尤其适用于筛选非线性机器学习的输入特征。然而,新的研究表明,对于部分非函数依赖情形它的检测效率存在不足。本文首先回顾并展开介绍 Chatterjee’s \(\xi\) 的具体原理和关键特性。最后介绍一种同样一致的、无需参数的独立性检验算法 \(\tau^*\) 作为替代方案。

在加密世界里,去中心化交易所(DEX)是一个美好的理想:它让任何人都能在无需许可、无需信任第三方的情况下,安全地保管并交易自己的资产。但在实现这个理想的路上,一直面临一个两难的选择。

穷则变,变则通,通则久。
市场之术,日新月异,其变无穷。高频做市,在微秒间追光逐电;链上协议,以数学构建流动性之池;期现套利,在不同时空寻找均衡之引力。凡此种种,法门万千。
然,大道至简,万法归宗。有一道焉,不执于术,而游于理,化繁为简,是为“广义流动性提供者”(LP)之修行。循此道者,其所得之通,乃见做市与套利,本为一体两面,互为其根。
此篇笔记,便是这场修行之记录。其所探寻者,非一招一式之工巧,而是贯通全局之道——一个统一所有流动性供给行为的底层框架。唯有如此,方可在这变动不居的市场中,建立长久认知,最终和光同尘。

本报告围绕2025年及未来A股市场低延迟交易的技术路径,系统梳理了从交易所、券商到客户端的关键环节。实现极致低延迟需要交易单元、极速柜台、低延迟券商及行情、网络、算法、硬件等多方面协同优化。监管新规也对技术实现和合规提出更高要求。报告结合最新技术与政策趋势,评估各方案延迟表现,为市场参与者提供参考。
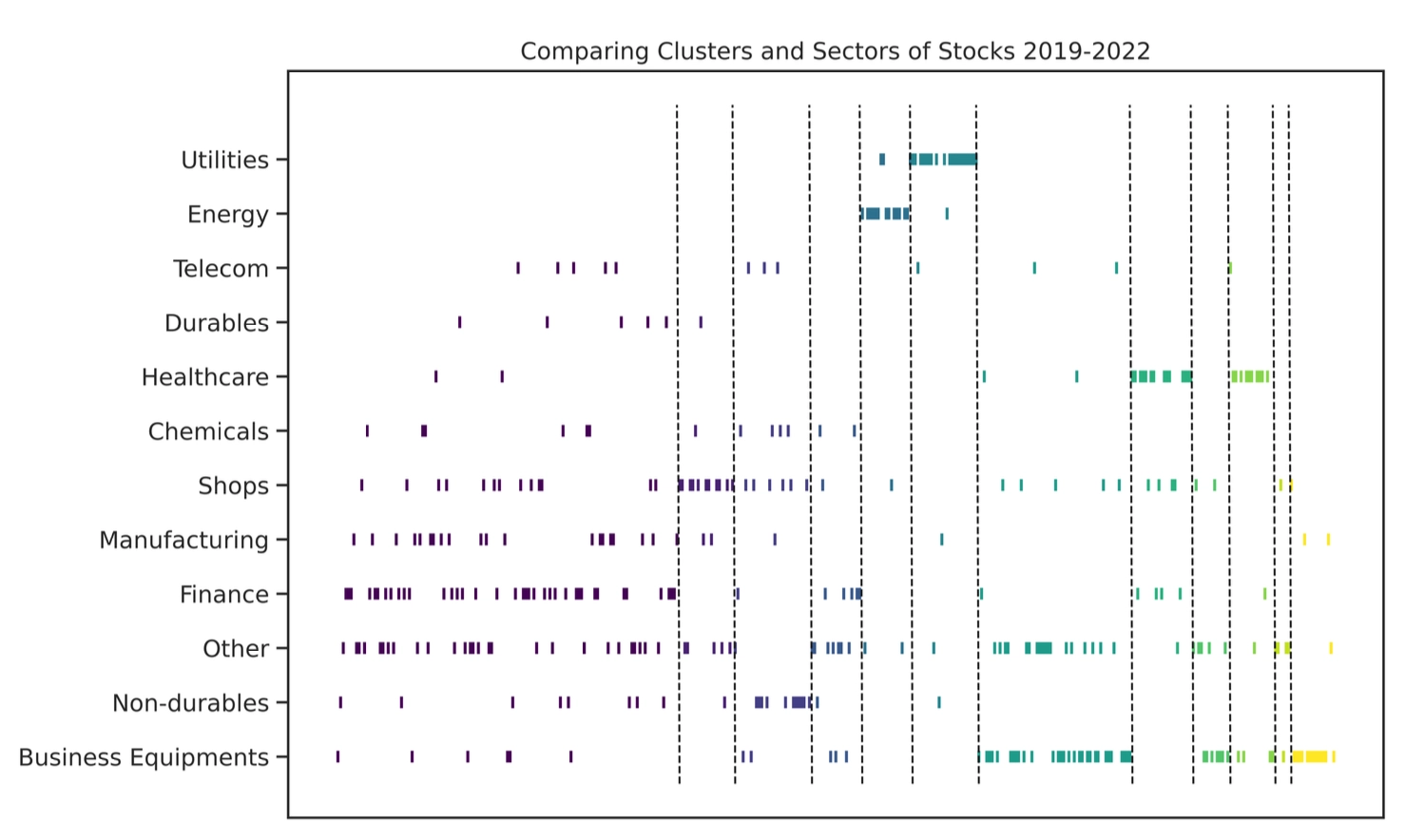
统计套利策略的核心在于对资产价格暂时性偏离的识别和利用。传统方法如配对交易(Pairs Trading)已广为人知,但如何高效地扩展到大规模资产组合并保持稳健性,一直是研究难点。牛津大学研究团队近期在论文《Correlation Matrix Clustering for Statistical Arbitrage Portfolios》中提出了一种创新分析框架:利用图聚类算法(Graph Clustering)对股票残差收益的相关性矩阵进行聚类,并在每个簇内构建均值回归的统计套利组合。实证表明,该方法能产生年化收益超10%、夏普比率显著大于1的策略。
电影产业作为典型的高不确定性市场,其票房表现对出品方的财务状况及市场估值具有直接影响。票房的 超预期程度 是衡量市场对电影接受度的关键指标,同时也是评估电影公司业绩的重要变量。然而,传统票房预测方法往往依赖静态的点估计模型,难以精准刻画票房随时间演化的动态特性,更难以量化票房超出市场预期的幅度及其不确定性,难以转化为可行的投资策略。
本策略通过资金费率机制和质押收益捕捉数字货币市场中的低风险套利机会。
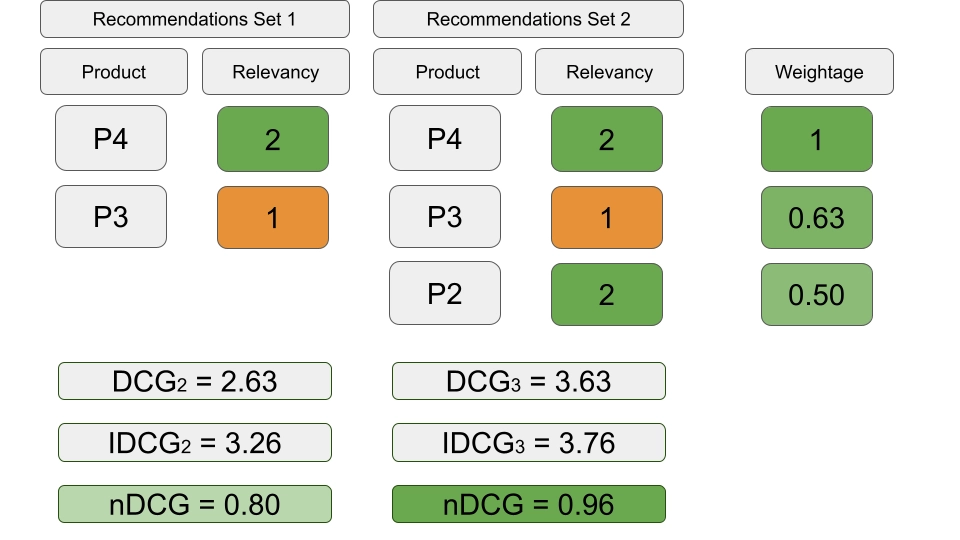
本文简要介绍了排序学习的背景、分类、性能度量,并归纳其发展历程中的几种经典算法。本文不追求深入每个技术细节,而是注重传递排序学习核心概念的直观理解,为LTR不同场景下的实际应用做铺垫。