正合奇胜——另类因子挖掘前瞻
随着中国量化产业发展与市场环境日趋成熟,传统量价数据衍生的定价因子被充分挖掘,已公开发表的研究报告就有成百上千,甚至有私募号称坐拥数万因子,引人拍案称奇。然而这些多如繁星的因子们只是若干本质因素的不同量化呈现,如非流动性溢价、特质波动异象等,并不能在特殊行情下分散风险。在极端情况出现时(如24年2月)大多数量价因子会集体失效或反转,给投资者造成更大的波动,今年业内私募表现也印证了这一点。从这个角度上说,这些alpha因子只是在贡献特殊的beta。
而要获取真正独立的超额收益,必须完成量化研究价值发现的本职工作,开发新因子,方法有三:
- 引入新数据
- 新的处理方法
- 对已有因子改进
在新因子的三种来源中,本文聚焦使用新数据+新方法构造另类因子,捕捉投资者有限注意力产生的错误定价,具体分为相似动量与文本分析两项。
相似动量
领先-滞后关系
由于建模和计算的复杂性,大部分因子都只利用个股数据,很少考虑股票间关联关系,即使有,也是作为对收益率模型的改进出现的,并不考虑具体的金融学意义。而作为准另类数据的代表,不同企业间收益率的领先-滞后关系考虑了动量在相似股票上的溢出效应。
| 文献 | 效应 |
|---|---|
| Hou (2007) | 行业动量(intra-industry effect) |
| Cohen and Frazzini (2008) | 重要客户动量(supplier-customer effect) |
| Cohen and Lou (2012) | 复杂公司动量(conglomerate lead-lag effect) |
| Lee et al. (2019) | 科技关联度(technological links) |
| Parsons, Sabatucci and Titman (2020) | 地理动量(geographic lead-lag effect) |
| Ali and Hirshleifer (2020) | 分析师共同覆盖(shared analyst coverage) |
上述文章从不同角度揭示了不同公司的收益率间存在的关联。这些企业间关联造成的超额收益的来源是投资者对关联信息的有限注意力所导致的反应不足。这一流派在《Technological links and …》一文的垂范下发扬光大,成为一种挖掘另类因子的主流范式。
统一视角
相似股票能影响股票未来的表现背后主要基于三个逻辑:
- 投资者认为相似的股票会有相似的表现,所以投资者会用与某支股票相似的股票过去的收益来推断其未来表现
- 如果一支股票过去表现好,但是投资者错过了这支股票,那么投资者会找相似的但还没有较大涨幅的股票,也就是说,和表现优秀的股票相似的股票需求会增加
- 如果投资者在某一类股票中赚到了钱,思维会有路径依赖,之后的投资依然会寻找相似的股票进行投资。
从目前已有的实证数据看,该逻辑在A股也是成立的,甚至更为显著。毕竟,这是一个可以因为常温超导出圈,“超导热”电脑散热器厂家暴涨的跟风市场。知名分析师朱剑涛曾指出
股票的涨跌不是各自独立的,而是以概念、板块的方式轮动炒作,当某一板块大多数股票近期都表现较好时,该板块滞涨的股票就有补涨的需求,相反,当某一概念股近期普跌时,该概念其他尚未下跌的股票也有补跌的需求。基于这个逻辑,当某只股票近期表现弱于其相似的股票,那么该股票在短期内存在补涨需求,可能会有正的超额收益,相反,当某只股票近期表现强于其相似股,近期有补跌的压力,可能会有负的收益贡献。
在统一视角下,相似动量等价于最近邻算法KNN,其构建可以分为三步:
- 定义股票间相关关系,分为三种情况
- 最简单的情况,已知行业分类/概念集合,取同集合的所有其他样本
- 基于邻接矩阵,关联关系由两者共同定义,如被相同分析师写过研报
- 基于嵌入,股票性质由自身信息定义,如历史价格序列、财报文本等
- 搜索K近邻,可能用到近似算法
- 根据K个最近邻N日表现、自身表现,计算相似动量因子=邻居加权平均-自身表现
图神经网络相关讨论 近年来随着图神经网络兴起,也有不少工作将其应用于股票关联关系挖掘。本文认为,收益率、风险模型层面应用图神经网络有其合理性,但在相似动量因子挖掘方面,把任务全权交给模型并不适合。
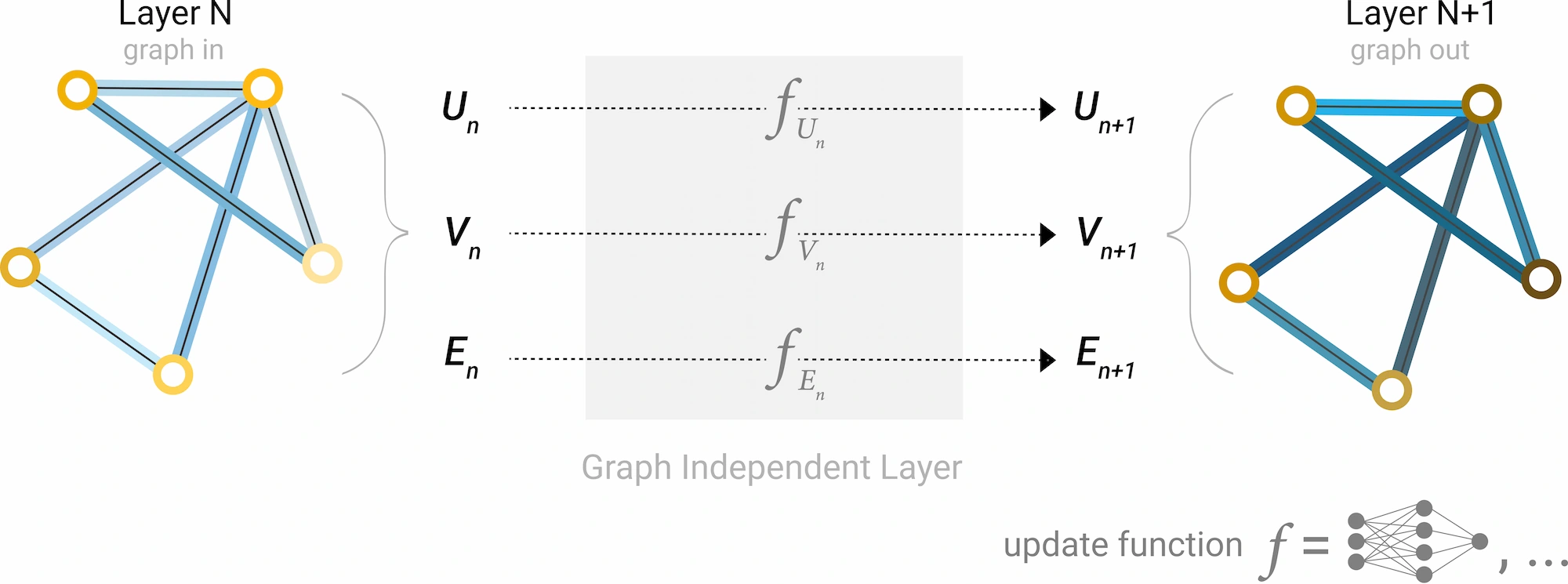
- 解释性 将更多的数据和异构邻边整合为一张图,能够挖掘出更复杂的内在联系,但对单一因子有效性的监控无从下手。
- 计算复杂度 KNN构造因子无须训练,比起神经网络动辄几小时数天的训练时长在计算性能上有显著优势
- 泛化性能 KNN数据更少,先验更强,不易过拟合,在邻边数量差异悬殊、关系动态变化的场景下较之神经网络理论上更易泛化。
总之,本文提倡使用KNN构造基础的,显著的相似动量因子,图神经网络在整合基础因子的模型层面挖掘更深层次的潜在关联关系,包括未被发现的动量溢出效应。
关联定义
- 行业/概念板块
- 直接计算邻接矩阵
- 基金持仓
- 分析师共同覆盖
- 机构调研
- 北向资金共同持仓
- 基于嵌入定义距离
- 历史收益率序列
- 低维基本面因子
- 资金流特征
- 企业营收相似性
- 专利数据
- 股票名称和代码相似(没错,还发了JFE, Attention Spillover in Asset Pricing)
文本分析
应用NLP技术分析海量金融文本也是计算机优势所在。
直觉上,投资者很难每天追踪数千只股票,投资者的有限注意力决定了有限的选择集,热门的股票在注意力的驱动下而获得大量资金流入。当某些股票吸引了市场上更多投资者的注意力,可能会导致股价短期的快速反应与高估,降低股票未来的回报。相反,有着利好消息的股票可能因为投资者的忽视在短期内被低估,而在后续的缓慢曝光中获得回报。在这个方向上,分析师研报因子已经取得不错效果,如华泰证券使用finbert构建的分析师研报选股因子。
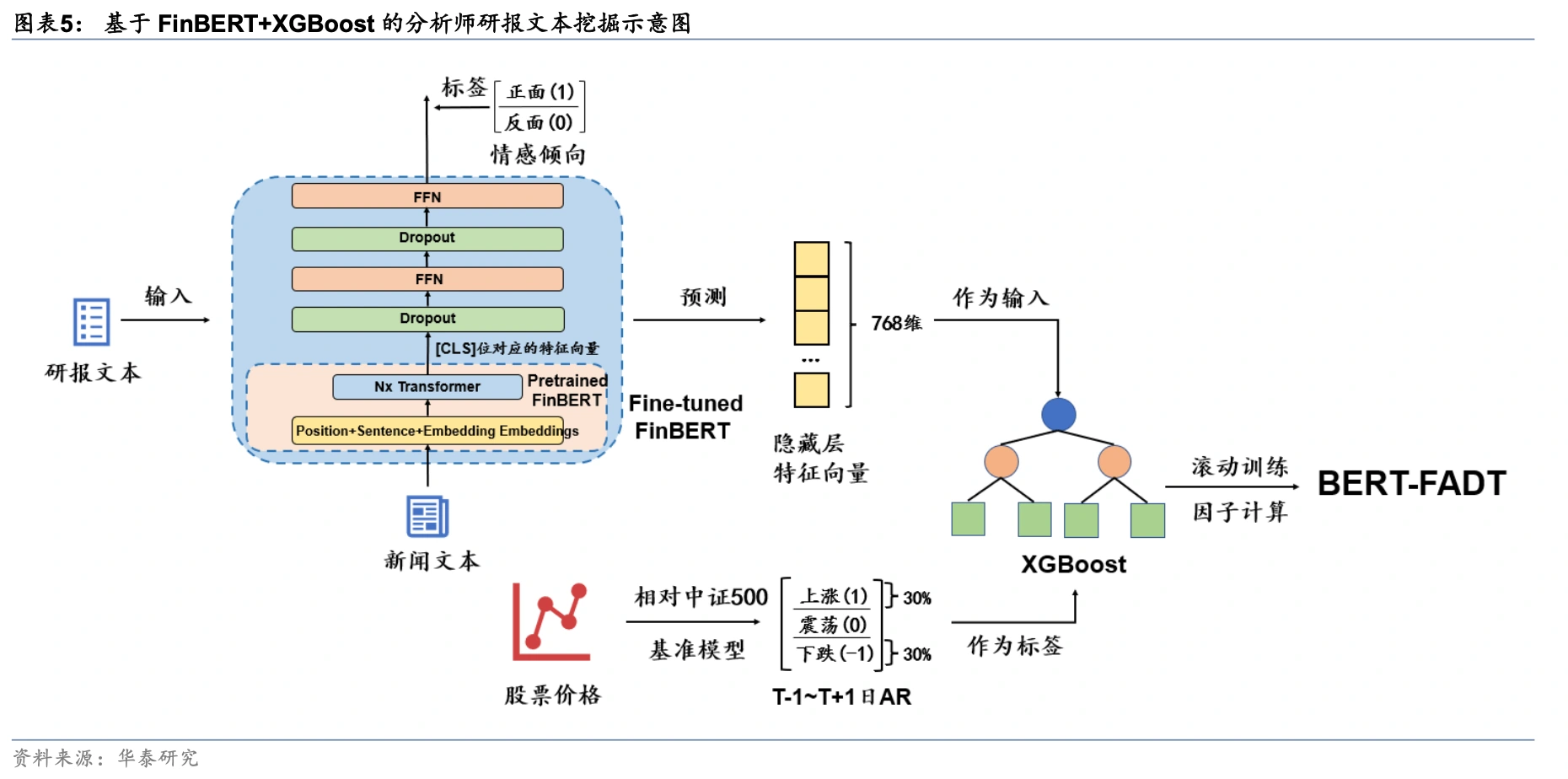
对分析师研报的文本分析本质上是寻找专业投资者更为看好的股票,发掘潜在价值。与之相对的也可以对噪声投资者关注度进行建模,如使用论坛热度和论坛情感强度构建负向因子。虽然已有不少论文和言报对论坛舆情进行分析,但大多延续情感判别的老路,最终组合绩效没有取得显著的结果。我认为此处有很大的提高空间,噪声投资者的情感受当前盘面影响大,与预期收益率相关性弱,应该重新思考针对性的建模方式。除此之外,投资者发言的情绪分歧是表针投资者异质信念的天然指标,可以有效应用于预测波动率。
金融文本分析可以和已有方法结合起来,如对科技关联度的改进就有使用专利文本嵌入的相似度,而不是简单的使用专利分类。又如提取公司公告中的企业经营情况计算文档向量,然后使用DRM模型计算风险因子——有着相似业务的公司,也应该有相似的未来表现。自然语言处理技术使得传统的因子分析和机器学习方法延拓到更广泛的场景中。
正合奇胜——另类因子挖掘前瞻