Quant4.0(四)系统整合与简化版量化多因子系统设计
在本节中,我们从系统角度回顾Quant 4.0,并研究如何将所有这些组件集成到一个系统中。下图展示了建议的Quant 4.0系统框架的架构,包括用于量化研究的离线系统和用于量化交易的在线系统。
本文是对论文Quant 4.0: Engineering Quantitative Investment with Automated, Explainable and Knowledge-driven Artificial Intelligence的部分翻译,有删改。原文地址
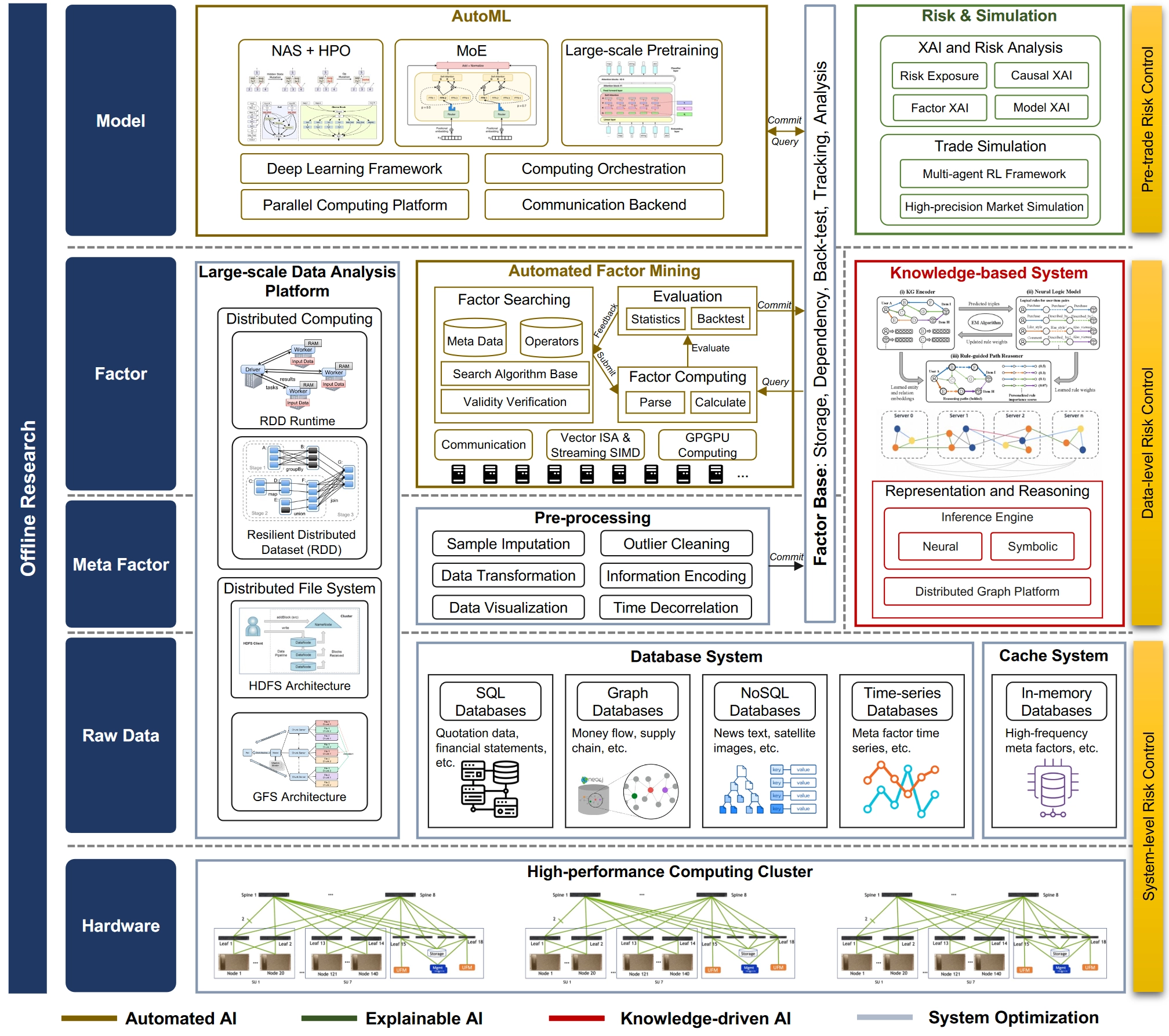
离线研究系统
Quant 4.0离线量化研究系统旨在提高量化研究的效率。它包含多个层次(硬件层、原始数据层、元因子层、因子层和模型层)和模块(高性能计算集群、数据系统、缓存系统、数据预处理、自动因子挖掘、基于知识的系统、大规模数据分析、AutoML和风险模拟)。

硬件平台架构
离线研究的底层硬件平台是一个高性能计算集群,由许多安装有共享存储[267]并通过高带宽网络[268]相互连接的计算节点组成。多个节点的组合汇聚了分布在各个单个节点中的计算能力,以支持大规模的量化计算任务。然而,通信瓶颈通常作为扩展计算能力的约束之一[269]。为解决这个问题,集群的网络拓扑采用分层结构,其中相邻的计算节点通过低层交换机连接,以增加集群的整体吞吐量。
量化研究任务有必须避免未来函数、适应风格迁移的特性,因此因子计算与建模一定是依赖局部数据的。如果要达到最高效率,在硬件层面就应该考虑利用Locality。
数据系统设计
Quant 4.0系统的数据层旨在收集海量金融数据,并为上层应用提供数据管理和查询服务。由于金融数据是异构且多模态的,因此在这一层中涉及不同类型的数据库系统来管理不同类型的数据。示例包括SQL数据库[270],时间序列数据库[271, 272],NoSQL数据库[273]和图数据库[274]。
SQL数据库存储和管理遵循[270]提出的关系模型的数据,其中数据存储在表示属性间关系的表中。大多数传统金融数据,如报价数据和财务报表,可以用这种类型表示,并适用于SQL数据库。
图数据库[275]旨在存储和管理由节点和边组成的图结构化数据。由于金融实体通过各种关系(如资金流动和供应链关系)相互连接,这样的图结构广泛存在于金融数据中。这些链接可能指示一些在邻域中共享的潜在模式。图数据库可用于存储和管理经济图、金融知识图和金融行为图。
NoSQL数据库[273]用于存储非表格数据,如键值对、文档和宽列。它适用于管理金融文本数据和图像数据,如财务报告文本、新闻文本、社交媒体文本、卫星和无人机图像等。
时间序列数据库[272]是专为快速访问、计算和管理时间序列数据而设计的数据库类型。这种类型的数据库引擎经过优化,以加速时间序列数据处理,例如计算实时收集的股票流数据,以及为高频交易计算时间序列因子等。此外,大量的金融数据需要高效的分布式存储系统来加速数据访问。为了进一步提高对高频刻度数据(限价订单簿等)的读/写速度,可以使用内存数据库[276]作为数据缓存,存储最常读取的数据。它节省了硬盘和内存之间的数据传输时间。
除了层特定的组件外,数据层、元因子层和因子层共享一个大规模数据处理平台,为各种数据驱动任务提供完整的解决方案和方便的模型。该平台的关键组件包括分布式文件系统,为分布式存储系统提供方便且可靠的数据访问,以及分布式计算引擎,为大量计算节点上的并行计算提供简单而高效的编程接口。具体而言,分布式文件系统如HDFS [264]采用由名称节点和数据节点组成的体系结构,在多个数据节点上执行数据复制以实现容错。另一方面,分布式计算引擎如MapReduce [277]及其包括Hadoop [278]和Spark [260, 261]在内的开源实现提供了用于并行计算任务的编程模型。通过将并行计算任务抽象为一组原始操作(例如MapReduce中的map和reduce以及Spark中的转换),编程工具易于开发人员使用,并且足够通用,能够处理许多常见的并行编程任务。
因子挖掘系统
原始数据具有不同的格式,但因子挖掘需要统一的输入格式。因此,与图12中的工作流程相对应,元因子层参与将具有不同模态的原始数据预处理为具有统一格式和适当值的元因子。因子层构建了自动因子挖掘引擎和自动因子挖掘管道。因子挖掘算法已在§2.2.1中介绍。这里我们介绍如何从系统角度规模实现因子挖掘。特别是,我们关注如何提高系统效率,以在单位时间内发现更多的“好”因子。
- 因子挖掘系统需要并行化架构以提高计算效率。
- 在因子生成过程中应实时检查因子的语法有效性,以减少由无效因子浪费的CPU时间。
- 在因子生成过程中应实时控制因子的多样性,以减少冗余因子的CPU时间消耗。
整个系统由分布式执行和计算加速的一些关键技术支持。分布式执行工具,如消息队列和分布式缓存,能够在多个节点上异步并行执行,从而保证系统的可伸缩性。计算加速技术,如CPU上的向量和流SIMD指令以及通用图形处理单元(GPGPU)[279]上的大规模并行计算,显着提高了dataframe操作的计算效率,从而增加了整个系统的生产力。 元因子层、因子层和模型层与因子库相连接,因子库是存储、计算、依赖管理、回测、跟踪和分析所有因子的集成平台(模型的输出也是因子)。在这些层中生成的因子以各种形式提交到因子库。具体而言,从原始数据预处理而来的元因子直接以dataframe的形式提交到因子库,其中包含有关它们的数据源和预处理方法的适当描述。通过自动因子挖掘生成的因子以符号表达式的形式提交到因子库,其中操作数是因子库中的其他因子。在模型层生成的模型输出也可以视为特殊的机器学习因子,可以与输入因子、模型架构、超参数和训练描述等一起提交到因子库。
把各类datetime-asset层级的数据视作因子,这种想法值得借鉴。
基于知识的系统
与因子挖掘系统并行,整体架构中还涉及基于知识的系统,以提供基于知识驱动的人工智能实践。如第4节所讨论,基于知识的系统包括两个模块:用于知识表示的知识库和用于知识推理的推理引擎。具体而言,分布式图计算平台被用作知识库,用于存储大规模金融行为图,而推理引擎则建立在其上,用于下游金融知识推理和决策制定。与传统的小型知识库相比,Quant 4.0中的金融行为知识图有可能增长到具有数十亿个节点和边的规模,因此需要一种灵活且可扩展的架构[280, 281]来存储和管理大规模动态图数据。因此,我们需要一个分布式图计算和管理平台,将整个知识图划分为分布在计算集群的不同节点上的多个子图。由于知识图的稀疏性,此划分专门安排为最大化数据局部性,其中位于同一分区的图节点比位于不同分区的节点更密集地连接[282]。 对于推理引擎,可以在该平台上实现知识图嵌入和基于规则的符号推理算法。
建模系统
模型层负责在部署到真实环境之前自动生成机器学习模型以及相应的风险评估和回测模拟过程。因此,该层涉及两个主要组件:AutoML模块和交易前风险分析和模拟模块。 AutoML模块在大规模分布式深度学习系统上实施自动模型生成算法。其技术堆栈的底层包括诸如CUDA [283]的并行计算平台,以及消息传递接口(MPI) [284]等通信后端,为分布式系统中计算节点之间的通信提供标准接口。技术堆栈的第二层,如PyTorch [285]等深度学习框架,通过硬件加速的线性代数操作和自动微分引擎提供深度神经网络的训练和推断的基本接口。此外,计算编排系统如pathways [286]将低级通信原语与深度学习框架功能结合起来,以实现更高层次的并行性,如模型并行和流水线并行,进而包装为上层程序的标准接口。技术堆栈的顶层包括模型生成算法的实现,如神经结构搜索和超参数优化(NAS+HPO) [287],专家混合(MoE) [265]和大规模预训练 [288, 289]。
风险和模拟模块在模型部署到真实交易环境之前识别和分析模型的潜在风险暴露。该模块实施可解释的人工智能技术,用于分析因子、模型和因果关系,揭示比BARRA模型解释的普通风险暴露更复杂的非线性风险暴露。此外,市场模拟器[290]用于测试交易策略的性能,比回测更精确,其结果可能受历史数据的偏见。具体而言,模拟环境系统[290]可以使用多智能体强化学习[291, 292]构建,其中代理模仿真实世界中各种市场参与者的行为[293]。
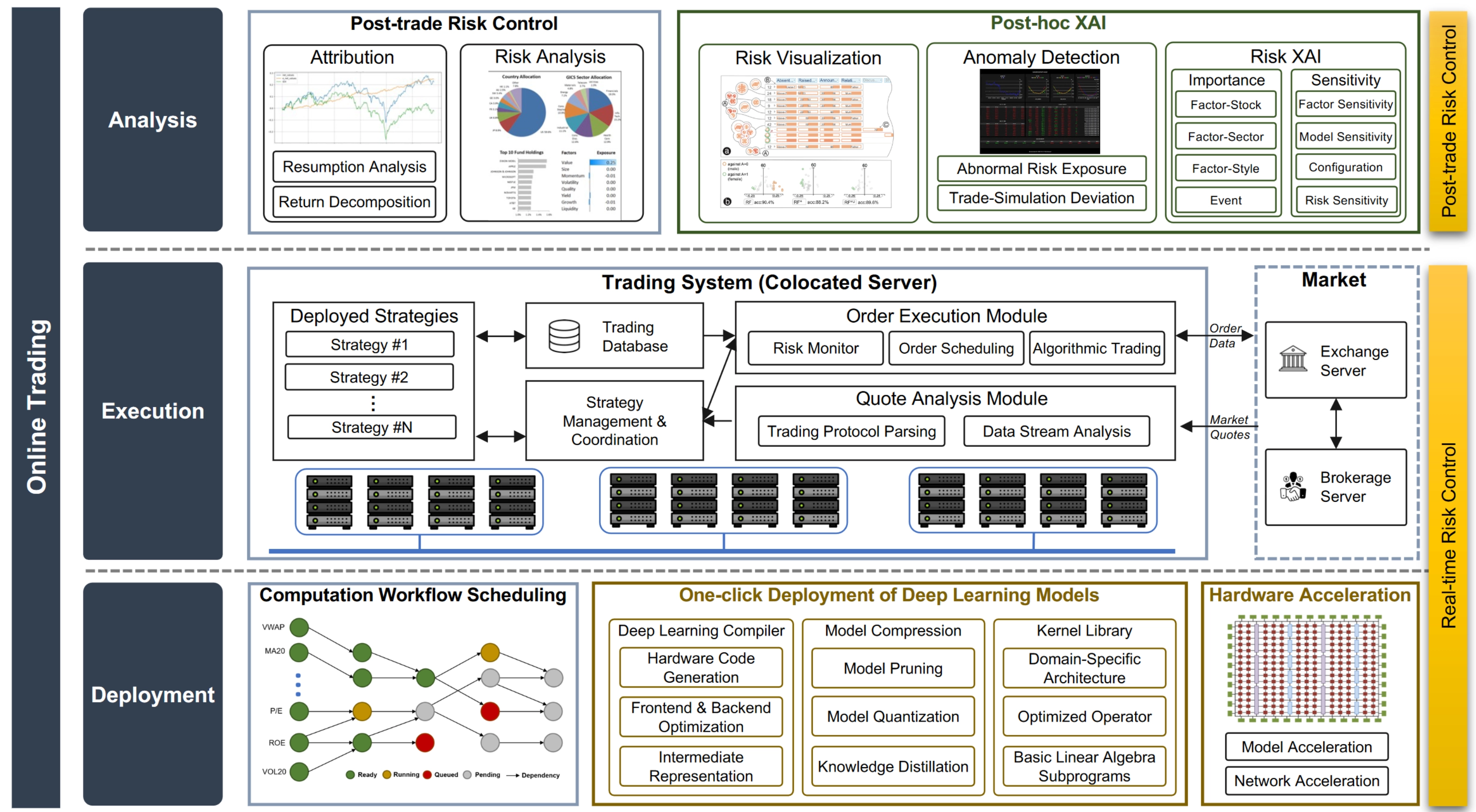
在线交易系统
在线交易系统专注于为真实交易部署投资策略和执行交易后分析,其主要目标是实现低交易延迟和高执行效率。交易系统包括三个模块:部署、交易和分析,我们在以下部分介绍它们的功能。
模型部署
部署层旨在实现技术“一键部署”的理念。它涉及计算调度模块、自动部署模块和可选的硬件加速模块。计算调度模块根据因子的内在数据依赖关系安排合理高效的计算顺序,形成了因子之间的有向无环图(DAG)。在计算调度系统中,只有在DAG上所有先前因子的计算完成后,每个因子才会开始其计算。由于以下原因,计算调度是一项繁琐的工作,应由系统自动化处理。
- 我们必须实时同步离线因子依赖与在线因子依赖,并保持它们的一致性。
- 因子数量可能迅速增长。想象一下当你累积了数百万个因子时会发生什么?对于任何量化研究人员手动部署这么多因子都是一场噩梦。
- 添加、删除和更新因子是因子维护的日常工作,这依赖于正确管理因子依赖关系。
合理!
从算法的角度来看,计算调度的问题可以看作是在依赖DAG上的拓扑排序。在实践中,调度程序旨在协调系统组件,并根据DAG上的计算顺序安排它们的执行。在这类调度系统的常见实现[294]中,采用了异步调度以提高整体执行效率。通过这种方式,待处理的步骤可以在前一步骤完成后立即开始执行。
自动部署模块旨在将离线研究中训练的深度学习模型部署到在线交易。它实现了2.4中讨论的算法技术。除了深度学习编译器和模型压缩引擎外,该模块还涉及优化的硬件内核库,提供基于硬件特性高度优化的常见数据处理和建模函数的实现。这类库的热门示例包括cuDNN [295]和MKL [296]。内核库中的函数通常包括用于科学计算的基本线性代数子程序(BLAS)[297],以及一些针对深度学习的优化操作符,如3卷积。这些实现专门根据领域特定架构[298]进行了优化,以最大化所使用硬件的潜力。 硬件加速模块旨在利用诸如可编程门阵列(FPGA)加速等特殊硬件技术,提高数据处理和模型推断的计算效率。在FPGA上实现的策略组件,如网络协议栈或具有自定义逻辑的机器学习模型,可以绕过通用硬件上不可避免的冗余逻辑,从而实现更低的延迟,并在交易中赢得对其他市场参与者的优势。然而,要在特定硬件上部署策略,通常需要大量的开发工作才能以令人满意的速度完成策略迁移。因此,高级综合技术[300, 301, 302]被开发出来解决这个问题。它们直接生成用于高级表示的寄存器传输语言,在高级语言中策略最初被实现。
交易执行
执行层将交易决策转化为实际在交易所执行的订单,其目标是尽量减少交易延迟,以捕捉市场中的瞬息机会。延迟可以分解为两部分:传输延迟是交易服务器与市场服务器(交易所服务器或经纪服务器)之间信号通信的延迟,计算延迟是行情接收与订单发送之间的延迟。为了减少传输延迟,交易系统通常部署在与市场服务器同地点的服务器上(例如经纪提供的机柜和机架)。为了减少计算延迟,交易系统必须通过各种软件和硬件加速技术在完整的策略流水线中进行优化,从数据收集到订单执行。
交易分析
分析层监视投资策略的执行并进行进一步的分析以进行调整。它包括一个负责普通性能监控的事后交易风险控制模块,以及一个事后可解释人工智能(XAI)模块,用于从AI的角度解释策略行为。事后交易风险控制模块执行回报和风险归因,旨在分析策略的表现,并揭示机器学习黑盒隐藏的内在风险结构。此外,事后XAI模块提供对投资策略的深入分析和解释。它通过分析所有策略组件的重要性和敏感性,提供彻底的风险分析,并可视化风险结果。
备注 风险控制是量化投资的核心任务之一,也是系统设计的主要考虑因素。在我们提出的工程框架中,风险控制的理念贯穿整个架构。具体而言,系统级别的风险控制体现在硬件和原始数据层中,其中底层硬件和原始数据的可靠性和稳定性是首要任务。数据级别的风险控制体现在元因子和因子层中,其中强调因子和知识的质量控制和管理。交易前风险控制体现在模型层中,要求模型具有鲁棒性和可解释性。实时风险控制体现在部署和执行层中,系统的交易行为受到限制,以避免意外情况。事后风险控制体现在分析层中,进行详细分析以提供对策略表现的全面而合理的洞察。
简化版量化多因子系统
本节是在原文基础上,针对个人、微型机构提出的一种alpha策略量化投资系统。主要特点如下:
- 充分整合开源社区资源
- 保持系统精简、成本可控
- 通过应用机器学习算法减少人力消耗

Quant4.0(四)系统整合与简化版量化多因子系统设计