嵌入式AI项目:小议未来信息社会与嵌入式系统的《位置》
高中时,我就对电脑配件十分痴迷。厂商发布的新品,我第一时间去了解,不同型号的特性差异,我了如指掌,商家对产品浮夸宣传图,我也爱不释手。手机淘宝的购物车,是我权衡成本性能的演练场;身边亲友的配电脑需求,是我学以致用的冲锋号。只是PC市场早已过了快速发展的年代,技术壁垒高,生态垄断导致产品趋同创新寥寥,让人渐渐乏了兴味。最近做了一个51单片机的小项目,顺便了解了目前市面上各式各样的单片机。技术门槛低、需求多样使得他们的芯片、存储、外设野蛮粗犷而又百花齐放,让我重温了那份乐趣。由此,我想使用单片机结合机器学习做一个小项目。
未来信息社会
想装机,没有需求也能创造需求,但是个人想做一个实用的嵌入式AI项目,就必须先思考它的立项背景、优势等。我的个人习惯是自上而下进行设计。首先我想勾勒出未来信息社会的轮廓,再设计一个理念先进的产品。因为首先,做传统产品一定远逊成熟产品。其次,不先进我也懒得做。
要预测未来,不妨回首过去。21世纪初,最流行的游戏是传奇、魔兽争霸、Dota,人们交流是在bbs,网吧则是普通人上网的重要场所。21实际10年代,iPhone4横空出世,从此智能手机变成了人手一台的标配,移动互联网时代开启了。人们只要低下头,随时随地接收信息,信息载体也从文字(2G,网络小说)升级到图片(3G)再到视频(4G,短视频)。同时请求量增大催生出云计算、边缘计算等新技术。而随着GPU算力飞越,显存激增,深层神经网络模型暴打支持向量机,成为人类解决最优化问题的屠龙宝刀。
由以上可以总结出两个重要趋势:第一,网络接入增长。从要去网吧上网到现在几乎所有人都已随时联网,下一步应当是物联网。第二,基础设施与需求相互促进。算力升级催化了深度学习,网络设施使能了愈发丰富的信息媒介,而人们海量需求又倒逼服务端技术革新。
以前服务模式的主流是C/S模型,人们应用云计算也只是想要更好的server罢了。

有人说,未来的信息社会就是5G+物联网+ABC(AI,BigData,Cloud Computing)。我对其中一些技术有些质疑,但发现把这些概念,和其他一些火热的概念结合起来,可以勾勒出未来AI应用模式与计算架构的部分轮廓。具体来说,我梳理了他们的关系,小胆预测了这幅图。

最底层是物联网设备,它们通过5G连接互联网(低时延,单位面积接入量大),产生前所未有的大量数据。以风力发电机监控设备运行状态为例,每几毫秒就会做一次采样,每天产生PB级的数据。这些数据被收集后,是培育人工智能模型的绝佳土壤。在编写模型的工程中,应当有统一的、易用的通用算子集,类似x86指令集,利于编程(可以被AutoML取代)与硬件实现。
右侧框图阐述计算模式,云计算可以提供弹性的几乎无穷的算力,适用于模型训练等场景。而边缘计算则适合需要稳定提供较小算力的场景,如持续采集图片并进行模型推断。但二者并非二元关系,虚线代指他们中间的过渡地带。比如,CDN对用户来说是云计算,对源站来说则是将资源推向端侧。
未来信息社会的计算架构就是一台多层次、异构的超级计算机。未来的AI模型会在数据层之上进行训练,根据需要下放到不同层级的计算节点上。
嵌入式系统的《位置》
分析完未来信息社会的整体架构,让我们详细分析一下嵌入式系统在其中的位置,以及怎么与AI结合。
优势
实时性&高可靠
作为实时采集数据的终端节点,直接对数据进行处理、运算不仅能在理论上确保计算时间,还能避免网络错误带来的麻烦。对于车辆控制,航空航天这些领域往往要求硬实时的系统。因此,原先机械控制的嵌入式系统可以考虑引入AI做一些正确性要求不严格的事情(感觉很有限)。
隐私保护
传输数据到云端,就会有信息泄露的风险。更重要的是,单片机无法运行复杂的加密算法,数据很容易被窃听。
降低带宽成本&功耗低
中国企业的上行带宽成本极高,在上文例子中,如果把风力发电机数据放到云端分析,会消耗大量时间与带宽成本,与此相比本地的AI芯片部署与功耗成本微不足道。因此数据抽象会是嵌入式AI非常好的应用场景,如安防监控中,只将时间+人数这种抽象后的信息发送云端,而不是完整视频。
挑战
空间与时间复杂度
机器学习模型通常参数量庞大(吃内存),计算量高(吃cpu),这对于嵌入式系统有限的性能而言往往是不可负担的。针对这一问题,@稚晖君 尝试在Cortex-M的MCU上跑起神经网络手势识别模型。[2.]
推理一个CNN模型最低需要什么性能的硬件呢?
最近想试试把以前搞嵌入式单片机的一些经验和最近在做的深度学习结合起来,正好前段时间看到新闻说新款iPhone和下一代Pixel似乎都要加入隔空手势识别功能,所以idea就来啦。
为了在Cortex-M的MCU上成功跑起CNN,用的模型是一个不到10层FCN网络,但是即便如此,对于主频只有不到100MHz,SRAM只有不到100K的单片机来说依然是极其吃力的,模型不做量化的话肯定无法做到实时的。
编程繁琐
各厂为AI计算推出了各自的NPU,编程人员对于不同芯片,不得不重新学习接口,从头编写程序。
研究方向
模型简化:算法上可以做的工作是模型量化、模型蒸馏、剪枝等。
通用算子集:矩阵运算、卷积运算、池化、激活等所有NPU几乎一定实现的操作可以统一成通用的算子集,会为软硬件开发带来极大便利。
软硬件协同设计:Google 在[1.] 中提出的定义是
The initial idea behind co-design was that a single language could be used to describe hardware and software. With a single description, it would be possible to optimize the implementation, partitioning off pieces of functionality that would go into accelerators, pieces that would be implemented in custom hardware and pieces that would run as software on the processor—all at the touch of a button.
可以说是非常超前的想法,实现起来困难重重。但已经可以朝这个理念努力起来了。
立项思路
对于我要做的这一项目,我有以下几点希望:
- 外观酷炫
- 理念先进
符合上一篇文章中总结的理念。 - 有一定实用性
- 原创工作
- 结合机器学习
硬件选型
系统级平台
运行完整的linux系统,等于一个迷你pc机,可以写python等高级语言,编程自然是最容易的。并且提供HTTP、DNS等上层网络服务非常方便,图像处理性能强大,有些甚至能支持4K输出。常用来实现软路由、网络电视、个人服务器等用途。典型产品有树莓派、orange pi,nano pi等,价格也可以做到十分低廉。
不过一般cpu跑深度学习模型并无优势,应该优先考虑调用网络API,可能失去了边缘计算优势。还有一个小问题就是用系统级芯片实现一些小任务太过浪费了。
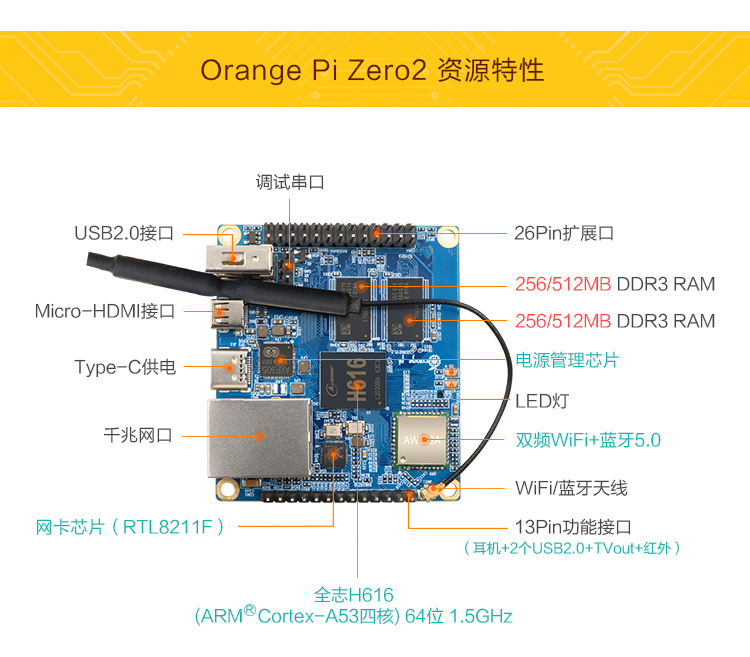
传统MPU
典型的有STM32,价格最低廉,性能最弱。虽然使用它做一个AI应用也是很有意义的,但投入产出比不高,且IO受限难有实用性。
高性能MPU
目前市场上有一些AI增强的MPU可供选择。其中佼佼者是嘉楠科技的K210芯片,功耗0.3W,28nm制程工艺,算力最大1TOPS,售价3美金,几乎平衡了性能、成本、功耗的不可能三角。它基于Risc-V 64位架构,双核心@400Mhz,额外具有卷积与FFT的硬件实现,安全性上实现了AES与SHA256。给人的感觉就是IC设计接近局部最优解,开源的Risc-V商用在如今时局下更显得十分顺眼。美中不足的是内存仅有8M,且实现的神经网络算子不是很合理。
详细了解K210:https://github.com/kendryte/kendryte-doc-datasheet
有sipeed的开发板可供选择。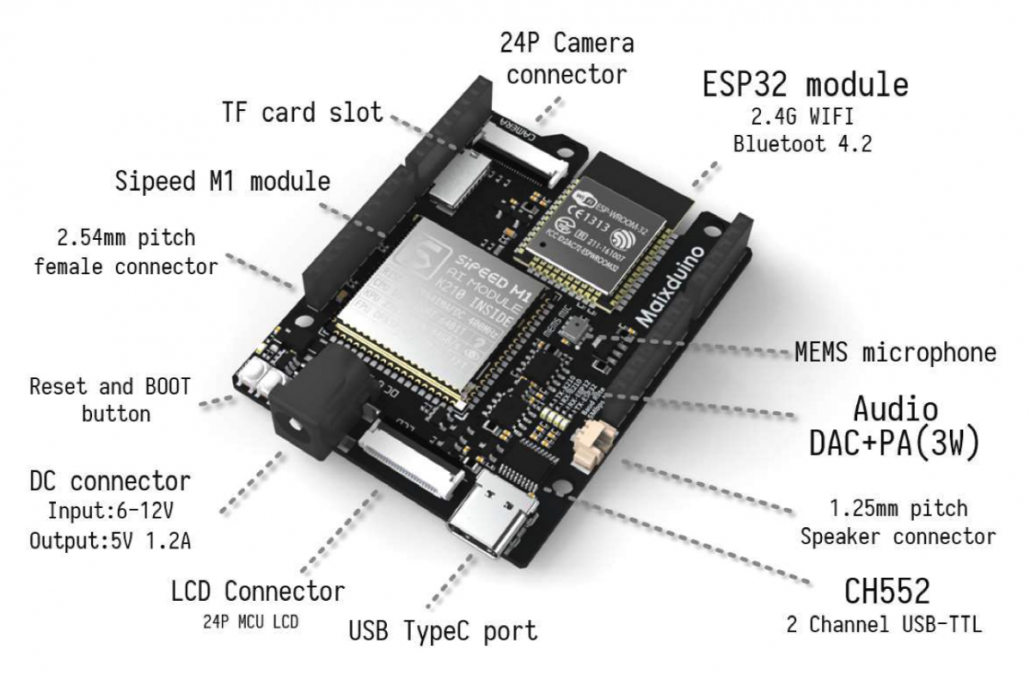
参考资料
[1.] De Michell G, Gupta R K. Hardware/software co-design[J]. Proceedings of the IEEE, 1997, 85(3): 349-365.
[2.] http://www.pengzhihui.xyz/2019/07/20/m4cnn/
嵌入式AI项目:小议未来信息社会与嵌入式系统的《位置》