大数据时代漫游指南
Don’t Panic
引言
这个社会存在着——或者说将会存在——一个问题,那就是:大部分人在大部分时间产生数据,同时受数据支配,却对此一无所知。针对这一问题人类生产了大量文章,但其中绝大多数是从各种数学符号的组合入手的——这很奇怪,因为无知的并不是这些数学符号。
本文的写作目的是让您——哪怕从没听说过微积分——掌握进入大数据时代所需的一切知识。尽管显得冗长,并且包含许多虚假或者至少是不够准确的信息,但它在两个极其重要的方面超越了那些更加高深和老派的学术著作。
第一,它是完全免费的;第二,在它的开头以大而友善的字体写着“Don’t Panic”。其内容也使得读者略过繁难的数学公式,直接获取高层次的总体概念,笔者愿称之为Math-free。
人工智能
当今世界,最脍炙人口的词汇莫过于AI(Artificial Intelligence,人工智能)。但鲜少有人知道什么是人工智能,在大多数时候,这个词只是装逼的咒语:
商汤科技以“坚持原创,让AI引领人类进步”为使命和愿景。
——著名AI创业公司 商汤科技
为业内人士所不齿:
你才做AI,你全家都做AI。
——商汤科技创始人 徐立博士
其实,这一概念太过宽泛,甚至众说纷纭,以理性和类人、过程与结果作为两轴划分,出现了四种定义:
- 像人一样思考
- 理性地思考
- 像人一样行动
- 理性地行动
电影、小说中的AI是往往从思考角度定义的,具有心智和意识,能根据自己的意图开展行动,这在学界被称为 强人工智能(Artificial General Intelligence,AGI) 。AGI因为艺术作品广为人知,但很可惜,由于技术水平限制和伦理问题,这并不是主流研究方向,讨论AGI如同讨论永生一般有些不正经的意味,未来很长一段时间内也难言“实现”二字。但DeepMind首席科学家David Silver认为,强人工智能可以通过结合 深度学习(DL) 与 强化学习(RL) 实现,即AGI=DL+RL,在后文中也会介绍另外两个概念。
“像人一样的行动”的路线上,典型代表是1950年被提出的图灵测试[4]:让人与程序通过文字聊天,看程序是否能以假乱真。1966年,Joseph Weizenbaum创建了一个似乎通过图灵测试的程序——ELIZA[5]。其程序通过避重就轻、含糊其辞等降智方法通过了这一测试(毕竟很难指出真实人类智商的底线),这显然意思不大。
已经以及将会大量应用的AI,是在某一特定领域可以“理性地行动”的程序,比如人脸识别、自动翻译、棋类游戏等。下面给出两种这个定义的表述,在下文中讨论的AI都遵循这种定义。
Intelligence is the computational part of the ability to achieve goals in the world. Varying kinds and degrees of intelligence occur in people, many animals and some machines.[1]
翻译:智能是实现目标的能力中的计算部分。人类,很多动物和一些机器中都会展现出各种类型和不同程度的智能。
Ideally, an intelligent agent takes the best possible action in a situation.[2]
翻译:理想情况下,智能体会在给定情况下采取最佳措施。
也就是说,人工智能是结果而不是手段,我们使用其他技术达到人工智能这一目的。比如,通过专家编写规则这种简单的方式,一样可以制造出人工智能,但这不是主流的做法。如今这一领域的核心手段,叫做 机器学习。
通常,我们会说自己是做机器学习的。
——商汤科技创始人 徐立博士
机器学习
1997年,Mitchell给出了机器学习(Machine Learning)的形式化定义
Machine learning (ML) is the study of computer algorithms that improve automatically through experience.
对于某类任务T和性能度量P,如果一个计算机程序在T上以P衡量的性能随着经验E而自我完善,那么就称这个计算机程序从经验E中学习。[3]
程序利用经验取得进步——这定义似乎和人工智能的定义一样泛泛,具体来说,机器学习的终极命题就是把所有实际问题转化为最优化问题——用一个数学式子作为性能度量,然后试图找到最优解。
在使用数学公式归纳实际问题的过程中,囿于数学与计算机表达能力的限制,最先要做的就是有所取舍与近似,对真实世界做出描述,近似后还剩余的从输入到输出的所有映射的集合被称为 假设空间。比如抛掷一枚硬币,预测其情况,在假设空间中,可能所有的假设输出都是正面或反面,但在真实世界中还可能是竖立的。而假设空间中的某一个假设,可以被称为 模型 ,比如一个每次都猜正面的假设。
从数据中学得模型的过程被称为”学习”或”训练”, 这个过程通过执行某个学习 算法 来完成,我们可以把学习过程看作一个在所有假设空间中搜索最优的过程[7]。机器学习算法有成千上万种,每种算法都有其独到之处,但脱离问题的实际背景,可以从数学上证明他们性能的期望是相等的(NFL定理, No free lunch theorem[6])。因此只有对于具体问题,讨论算法的优劣才有意义,不存在最好的算法。
在选定一种算法之后,通过训练——即上文中的“自我完善”——最终会产生一个可以应用的结果,也即确定的假设,称之为 模型,它可以接收输入,对外输出。比如说一个程序输入身高与体重,给出对于性别的预测,那么这个程序是一个模型。而它所对应的算法则可以是,统计数据集上三者一起出现的频率,对于给定的身高体重,查询男女比例,给出多者作为结果,以期超越胡乱猜测。
看了这么多,你可能还是云里雾里——究竟怎么实现机器学习?在实践过程中,方法五花八门,但可以分为三个基本学习范式,下文会逐一介绍:
- 监督学习
- 无监督学习
- 强化学习
而平常被频频提及的深度学习,并不是一种范式,而只是机器学习中的一种方法。如果说机器学习是实现人工智能的重要手段,那么深度学习之于机器学习,就如同机器学习之于人工智能。深度学习技术带来的性能突破是如此惊人,以至于直接导致了近年的AI热潮。
以上提及的概念都被整合到一张关系图中
监督学习
我们首先介绍最符合直觉的监督学习(supervised learning),在监督学习中,必须有标注过的数据集,或者把已有的结构化数据中的某些列作为预测的目标。算法先通过学习标注过的数据集(即训练集)来调整模型,再把模型应用于未被标注的数据集(即测试集)。监督学习主要分为两类任务:分类问题与回归问题。
考虑这样一个数据集:
| Id | Gender | Height(cm) | Weight(kg) |
|---|---|---|---|
| 1 | Male | 187.6 | 99.7 |
| 2 | Male | 174.7 | 66.9 |
| 3 | Male | 188.2 | 87.7 |
| 4 | Male | 182.2 | 90.7 |
| 5 | Male | 177.5 | 85.1 |
| 6 | Female | 149.6 | 42.1 |
| 7 | Female | 165.7 | 58.3 |
| 8 | Female | 161.0 | 54.0 |
| 9 | Female | 163.8 | 52.9 |
| 10 | Female | 157.0 | 53.5 |
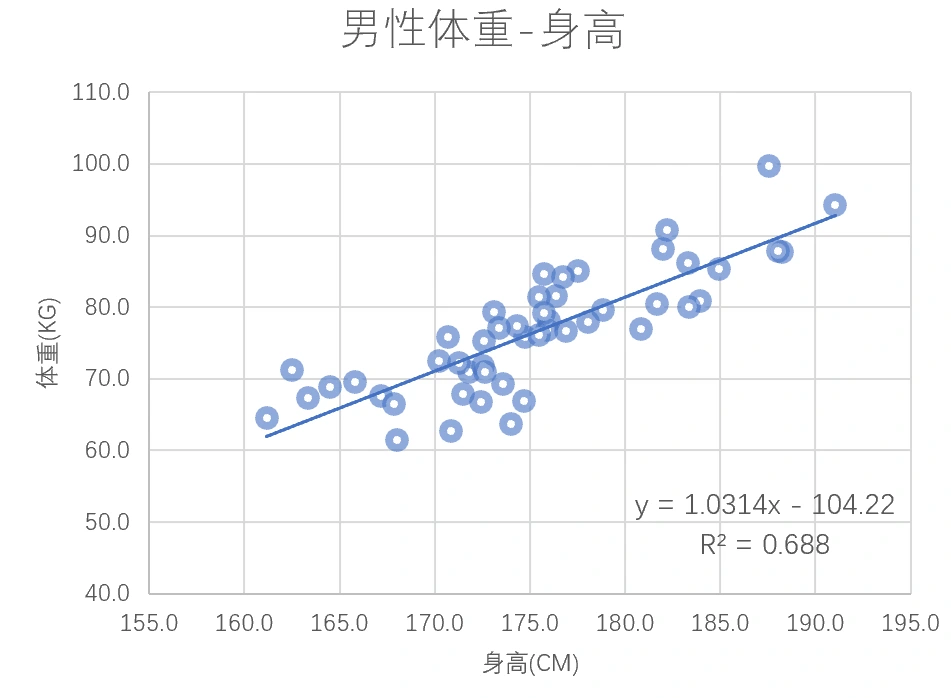
那么我们可以试图解决这样一个预测连续数值的回归问题:利用男性的身高\(x\)预测其体重\(y\)。虽然十分简单,但这展示了一次完整的监督学习过程。
- 假设\(x\)和\(y\)的关系
- 设定目标函数用于评价模型
- 调整模型的参数,使得目标函数最优
在这个例子中,我们是这样做的
- 我们假设他们是简单的线性关系,用直线:\(y=ax+b\)表示
- 目标函数是最小化均方误差,即离散的点到直线的纵向距离的平方和最小
- 而找到最好的直线的优化算法是最小二乘法,计算后最终输出的模型是\(y=1.0314x-104.22, R^2=0.688\)。\(R^2\)系数是一个常用的评价回归模型的指标,介于0~1之间,越高代表拟合得越好。
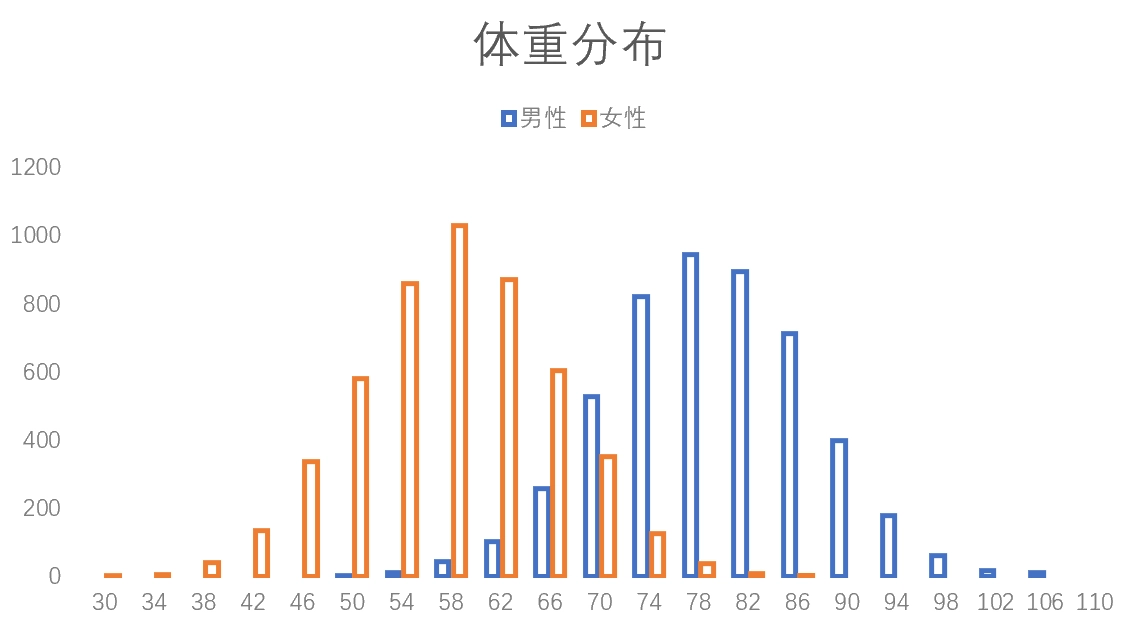
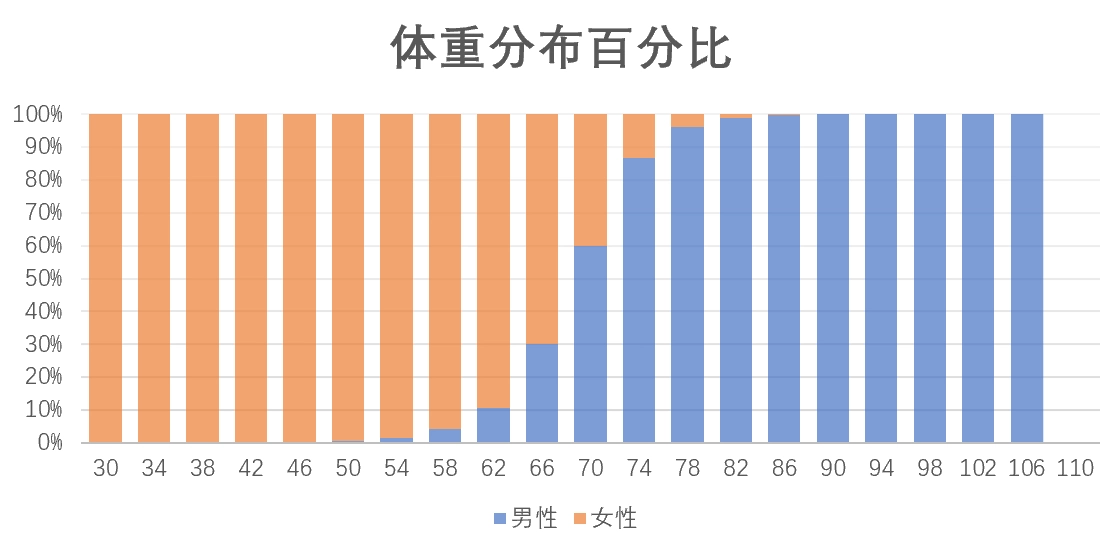
利用这个数据集也可以做一个二分类问题:输入体重\(x\),输出性别\(y\)。经典的频率学派的做法是先绘制出训练集体重分布情况,并将此作为真实世界的分布规律。对于给定的新的\(x\),把图中对应的男女比例作为真实概率预测。比如体重70kg,则认为有70%概率是男性。对于更高维度的输入,比如同时输入身高、体重、年龄,方法也是类似的。
进一步了解解决分类问题的算法,可以参考本站其他文章:
- ID3决策树 https://heth.ink/2020/id3/
- 逻辑回归模型(LR) https://heth.ink/2020/logisticregression/
无监督学习
在现实世界中,有标记的数据集是极少的,真实数据大多是无标记的、杂乱无章的。通过人力进行标注不仅耗费巨大,而且往往是不可能的。因此机器学习中有这么一类算法,不需要借助真实标记就能从数据中习得经验,输出模型,被称为无监督学习。如果说监督学习主要解决回归与分类问题,无监督学习的任务任务则主要是聚类与降维。
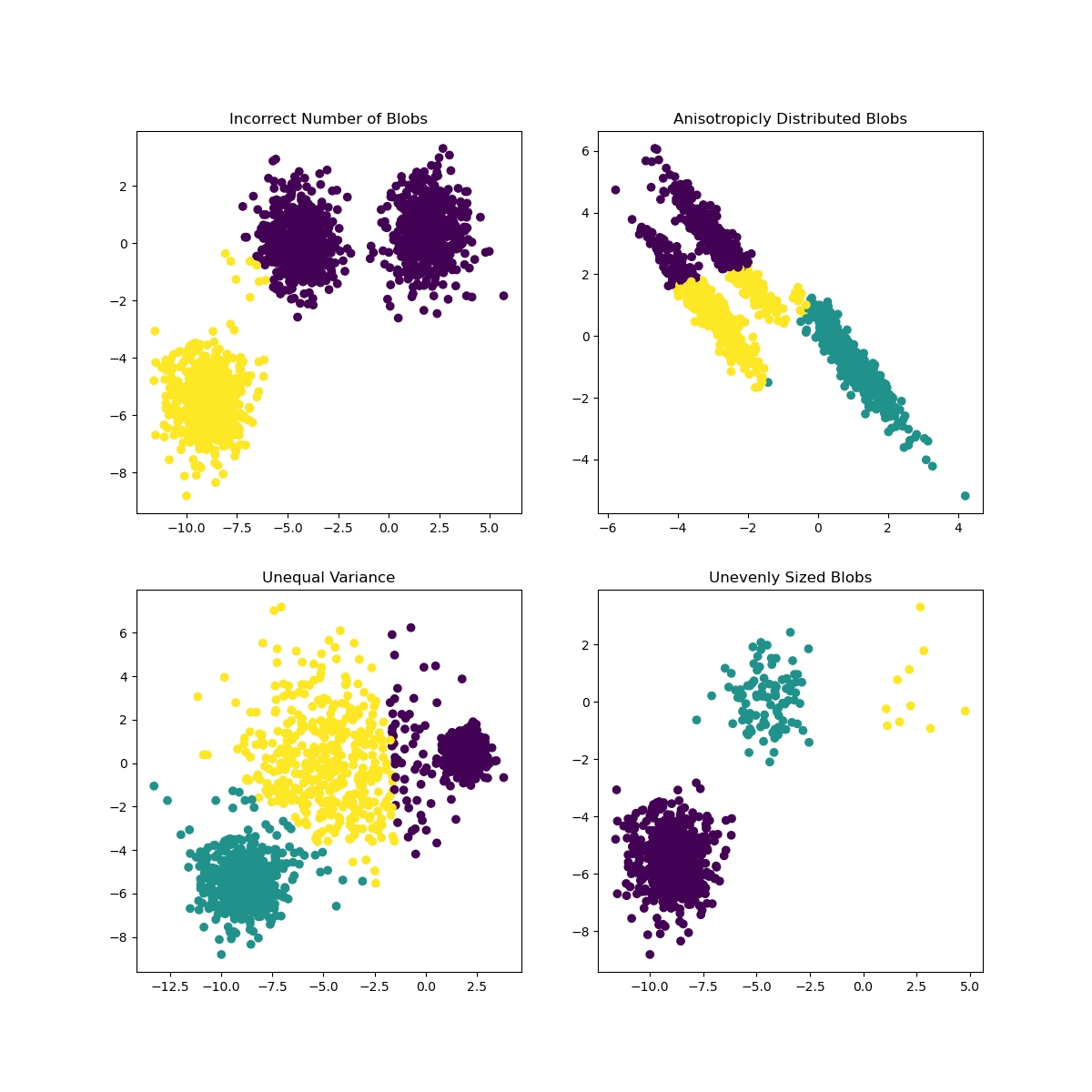
先说聚类,在二维平面上或者三维空间中,人很容易把有规律聚集的点划分出来,而在高维空间则就力有不逮。聚类算法是自动化这一过程的算法,如图中[8]所示,先验知识(算法与参数)与数据分布不同,聚类结果参差不齐。
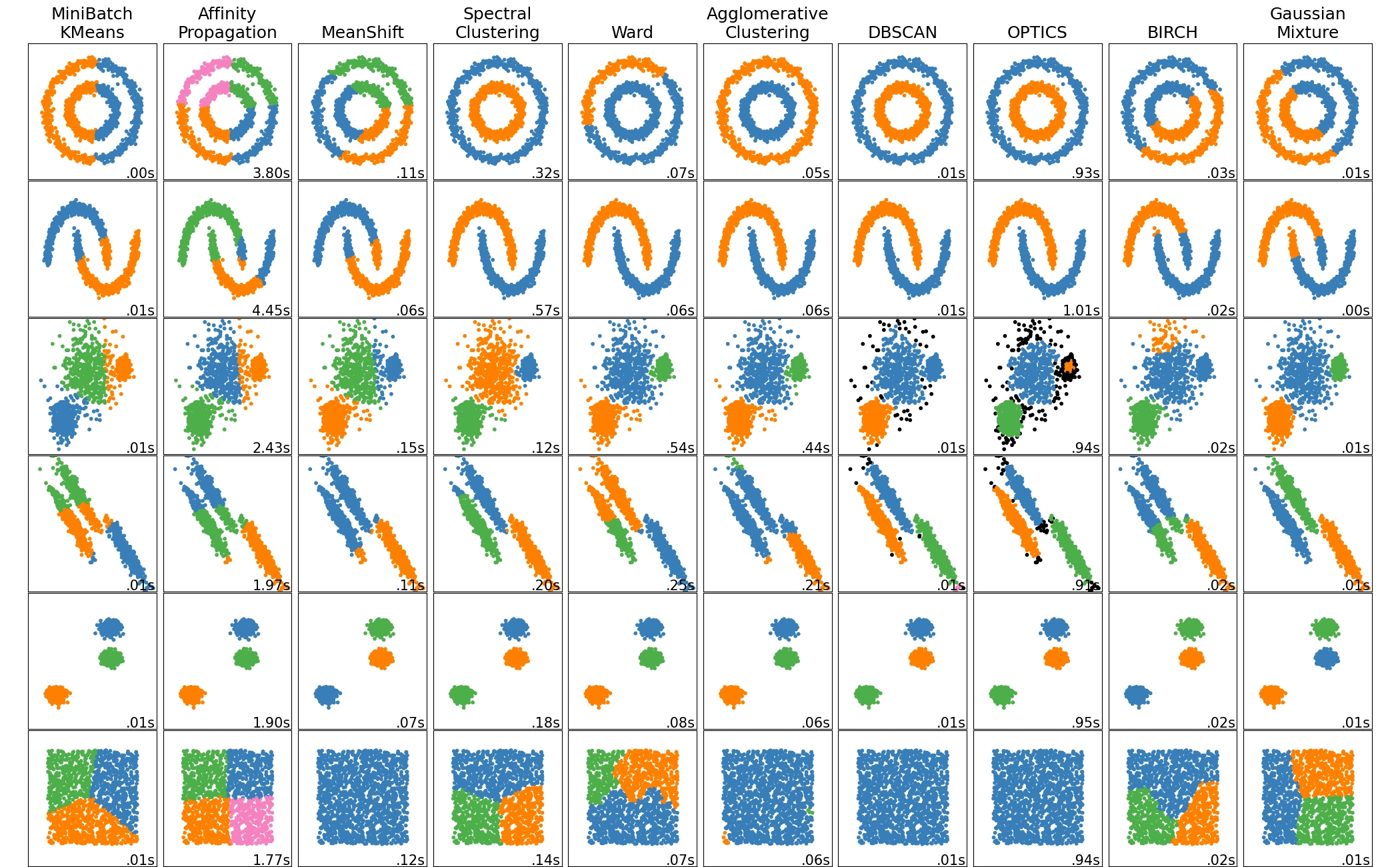
另一类任务是降维,其中最著名的是鸡尾酒会问题。「鸡尾酒会问题」(Cocktail Party Problem)诞生于 1953 年,是语音识别领域的经典问题,指是人们在鸡尾酒会中交谈,语音信号会重叠在一起,机器需要将它们分离成独立的信号。
强化学习
强化学习讨论的是如何训练智能体,使其在复杂、不确定的环境中最大化获取的奖励。如图所示,智能体从环境中获取观测,根据策略采取动作(决策),环境给出反馈,并且返回新的状态。强化学习与监督学习、无监督学习的最大区别有两点:
- 对环境的观测通常是连续的,有极强的关联性,不满足独立同分布。
- 强化学习必须探索环境、获取反馈,以调整策略,而反馈常常是延迟的。监督学习中,模型的所有输出都能计算一个对错或是误差程度,但在强化学习中,无法判断当前动作好坏,可能一百步之后才能证明策略是错的。
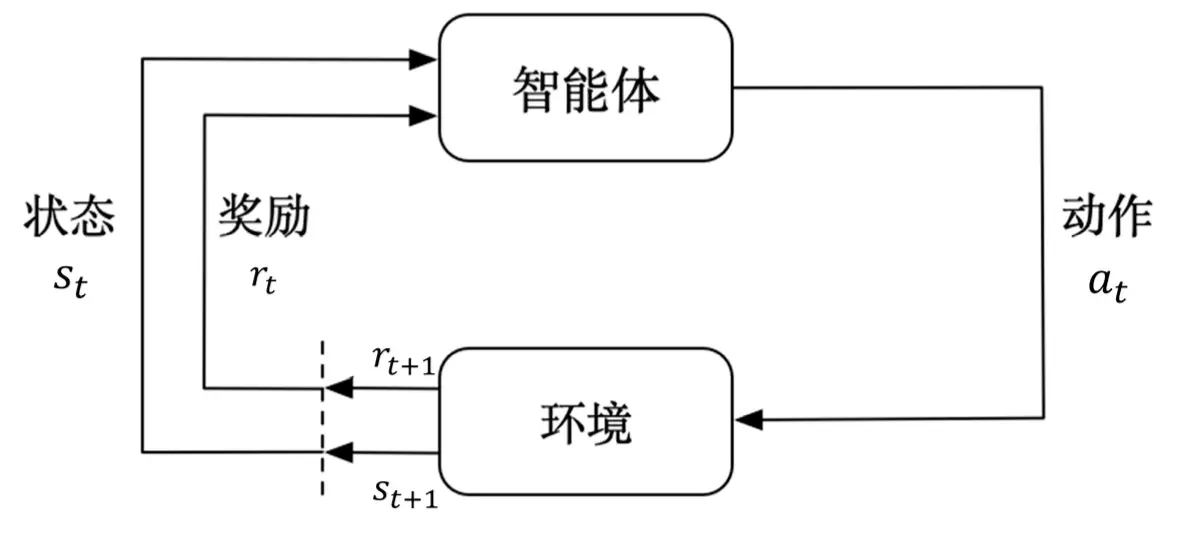
对于一个强化学习智能体,它可能有一个或多个如下的组成成分。
- 策略(policy)。 智能体会用策略来选取下一步的动作。
- 价值函数(value function)。 我们用价值函数来对当前状态进行评估。价值函数用于评估智能体进
入某个状态后,可以对后面的奖励带来多大的影响。价值函数值越大,说明智能体进入这个状态越有
利。 - 模型(model)。 模型表示智能体对环境的状态进行理解,它决定了环境中世界的运行方式。
智能体至少需要学习策略或者价值函数,才能进行决策,学习前者的算法被称为policy-based agent,后者被称为value-based agent,同时学习两者的算法是actor-critic agent。对“模型”的学习则是可选的,取决于是否能对下一步的状态和奖励进行预测。强化学习算法也可以分为model-based和model-free两种。
参考资料
[1.]Prof. John McCarthy of Stanford University http://jmc.stanford.edu/artificial-intelligence/what-is-ai/index.html
[2.] Russell, S., & Norvig, P. (2002). Artificial intelligence: a modern approach.
[3.] Mitchell, Tom (1997). Machine Learning. New York: McGraw Hill. ISBN 0-07-042807-7. OCLC 36417892.
[4.]Turing, A.(1950). Computing Machinery and Intelligence.Mind, LIX (236): 433–460.
[5.]Weizenbaum, J. (1966). ELIZA—a computer program for the study of natural language communication between man and machine. Communications of the ACM. 9: 36–45.
[6.]Wolpert, D. H. and W. G. Macready. (1995). “No free lunch theorems for search.” Technical Report SFI-TR-05-010, Santa Fe Institute, Sante Fe, NM.
[7.]周志华. 机器学习[J]. 2016
[8.]Scikit-learn: Machine Learning in Python, Pedregosa et al., JMLR 12, pp. 2825-2830, 2011.
大数据时代漫游指南