基于逐笔成交数据的股市资金流因子——雄关漫道真如铁
不同于成交量因子考察股票某一时间段内的交易量整体,本篇资金流因子基于逐笔成交数据计算,研究交易形成的微观结构特征(如交易对手是大单还是小单,挂单金额分布等)。逐笔成交数据量较大,计算因子颇具工程挑战,本文首先介绍基于单机的计算框架,然后简单总结资金流因子研究成果。
逐笔高频因子单机计算框架
如果考虑全市场股票日频量价数据,数据量等于股票数*交易日数量,每年不过一百多万条,若干年的因子计算可以在一个数据表中轻松完成。此前介绍的高频因子多是基于高频快照数据,由于高频快照数据可以容易地聚合到分钟级别并进行缓存,数据量虽上升两个数量级,但每年几亿条的数据规模处理对现代处理器仍不算难。而逐笔成交数据量则又上升了两个数量级,每天近一亿条撮合成交记录,每年约数百亿条,未压缩时占用约1TB存储空间,而一次因子计算至少需要处理千亿规模数据。其数据格式如下,每条记录是某一买单与卖单的一次撮合成交数据,包括双方的限价、挂单量、成交方向和成交量等信息。因为我们研究资金流特征,通常要把某一买单/卖单产生的交易记录聚合到订单维度。
| date | asset | time | Type | Price | Volume | SaleOrderID | SaleOrderVolume | SaleOrderPrice | BuyOrderID | BuyOrderVolume | BuyOrderPrice | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2022-01-10 | 000001.SZ | 09:25:00 | B | 17.29 | 100 | 1 | 100 | 15.48 | 1 | 8800 | 18.92 |
| 1 | 2022-01-10 | 000001.SZ | 09:25:00 | B | 17.29 | 300 | 2 | 300 | 15.48 | 1 | 8800 | 18.92 |
| 2 | 2022-01-10 | 000001.SZ | 09:25:00 | B | 17.29 | 1200 | 3 | 1200 | 15.48 | 1 | 8800 | 18.92 |
| 3 | 2022-01-10 | 000001.SZ | 09:25:00 | B | 17.29 | 500 | 4 | 500 | 15.48 | 1 | 8800 | 18.92 |
| 4 | 2022-01-10 | 000001.SZ | 09:25:00 | B | 17.29 | 1700 | 5 | 1700 | 15.48 | 1 | 8800 | 18.92 |
逐笔数据可得性与处理难度足以让普通投资者望而却步,理论上,这也应该成为专业投资者的信息优势、alpha来源。本节先不论其中蕴含多少有价值信息,仅讨论工程上如何在不使用分布式系统的前提下,使用cpu从逐笔数据计算天级别选股因子。传统上对TB级数据是使用大数据分布式计算系统,但不管是自建,还是使用云服务,其维护和使用成本都是个人投资者、小型机构难以负担的,而且会在天级别因子、高频因子间产生割裂。
至于为什么不采用gpu,则有以下几点原因:首先,虽然gpu的浮点性能远胜cpu,但受限于显存,它能处理的数据量往往是cpu的几分之一。其次,CuDF不会优化查询。以上两点导致其综合计算时间不必然快于cpu。最后,由于微架构差异,gpu在双精度浮点和复杂操作上的性能不佳。本文的测试环境大致是目前(2024.1)民用PC的扩展极限。
- cpu: 13900kf
- ram: 128 GB 3200Mhz双通道
- disk: 4TB ssd*2 raid0
高性能DataFrame 目前我的整个因子投研框架是基于Polars库搭建的,作为一个2020年诞生的年轻DataFrame库,polars保持易用性的同时,达到了一流的性能水平,革除了pandas的诸多弊病。其主要特点包括:
- 高效:Polars是从头开始设计的,紧密接近底层机器,并且没有外部依赖。
- 易用:用户以预期的方式编写查询。Polars在内部将通过其查询优化器确定最高效的执行方式。
- 离线处理:Polars通过其流式API支持离线数据转换,允许您在不要求所有数据同时存在于内存中的情况下处理结果。
- 并行处理:Polars通过在可用的CPU核心之间划分工作负载,充分利用了计算机的性能,无需任何额外的配置。
- 矢量化查询引擎:Polars使用Apache Arrow,一种列式数据格式,以矢量化方式处理查询,利用SIMD来优化CPU使用。
日内-日间二阶段计算 出于充分利用数据局部性的考量,框架分天存储当日数据,第一阶段执行单日数据处理,聚合为天级别初步结果,第二阶段处理初步结果的日间关系。这样做能极大提高计算性能,降低内存峰值。
缓存与采样 “聚合到订单维度”这样的操作十分频繁,因此框架会用硬盘缓存中间结果。为了在因子修改后得到实时反馈,提升研究效率,还支持对订单数据做10%抽样,实测结果与全量计算差异不大。
| date | scmc | SaleOrderID | time | OrderVol | OrderPrice | Volume | Amount | ActiveAmount | ActiveVolume | OrderAmount | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2022-01-10 | 000001.SZ | 4 | 09:25:00 | 500 | 15.48 | 500 | 8645 | 0 | 0 | 7740 |
| 1 | 2022-01-10 | 000001.SZ | 11 | 09:25:00 | 200 | 15.48 | 200 | 3458 | 3458 | 200 | 3096 |
| 2 | 2022-01-10 | 000001.SZ | 24 | 09:25:00 | 100 | 15.48 | 100 | 1729 | 1729 | 100 | 1548 |
| 3 | 2022-01-10 | 000001.SZ | 56 | 09:25:00 | 1000 | 15.48 | 1000 | 17290 | 17290 | 1000 | 15480 |
| 4 | 2022-01-10 | 000001.SZ | 61 | 09:25:00 | 1800 | 15.48 | 1800 | 31122 | 31122 | 1800 | 27864 |
基于逐笔成交的资金流因子
克服因子计算的高墙深池之后,资金流因子的效果只能说是喜忧参半。整体上,资金流因子做短周期(一周以内)预测的信息系数远不如换手率、短期反转等简单日频因子,缺乏简单明晰的alpha来源。但令人略感欣慰的是,技术面因子往往空头收益远高于多头,应用价值有限,这种现象在资金流因子中出现得较少。
订单分布
在获取买单/卖单数据后,计算其分布特征是很自然的想法。股票单日订单分布近似于Pareto分布,因此比较其分位数之比等价于比较分布参数。因子有显著的选股能力,分布越不均衡,未来预期收益率越大。类似的,还可以计算订单分布的信息熵,该因子具有显著的负向选股能力。
大单冲击
“大单买入均价偏离”、“大单推动涨幅”因子都刻画了大单买入对价格造成的冲击,大单导致的价格上扬都具有极强的负向选股能力,但多头收益不佳。这一现象最初由开源证券团队在反转因子的改进中提出。
大小单资金流差异
通常认为大单对应“主力”,小单对应“散户”,大单资金流有正向选股能力,小单资金流则是反向指标。针对这一异象的刻画方法远不如其他异象般统一清晰,各家界定标准与加工手段均有不同。如开源证券提出大小单资金流强度因子,分别计算中大单净流入、小单非主动净流入强度(很奇怪吧?没有理论,数据挖掘的结果),然后剔除与反转因子的相关性以提升性能。东方证券计算剔除超大单后,大单买入比例。类似的因子还有小单主动买入占比、小单主动成交净流入。
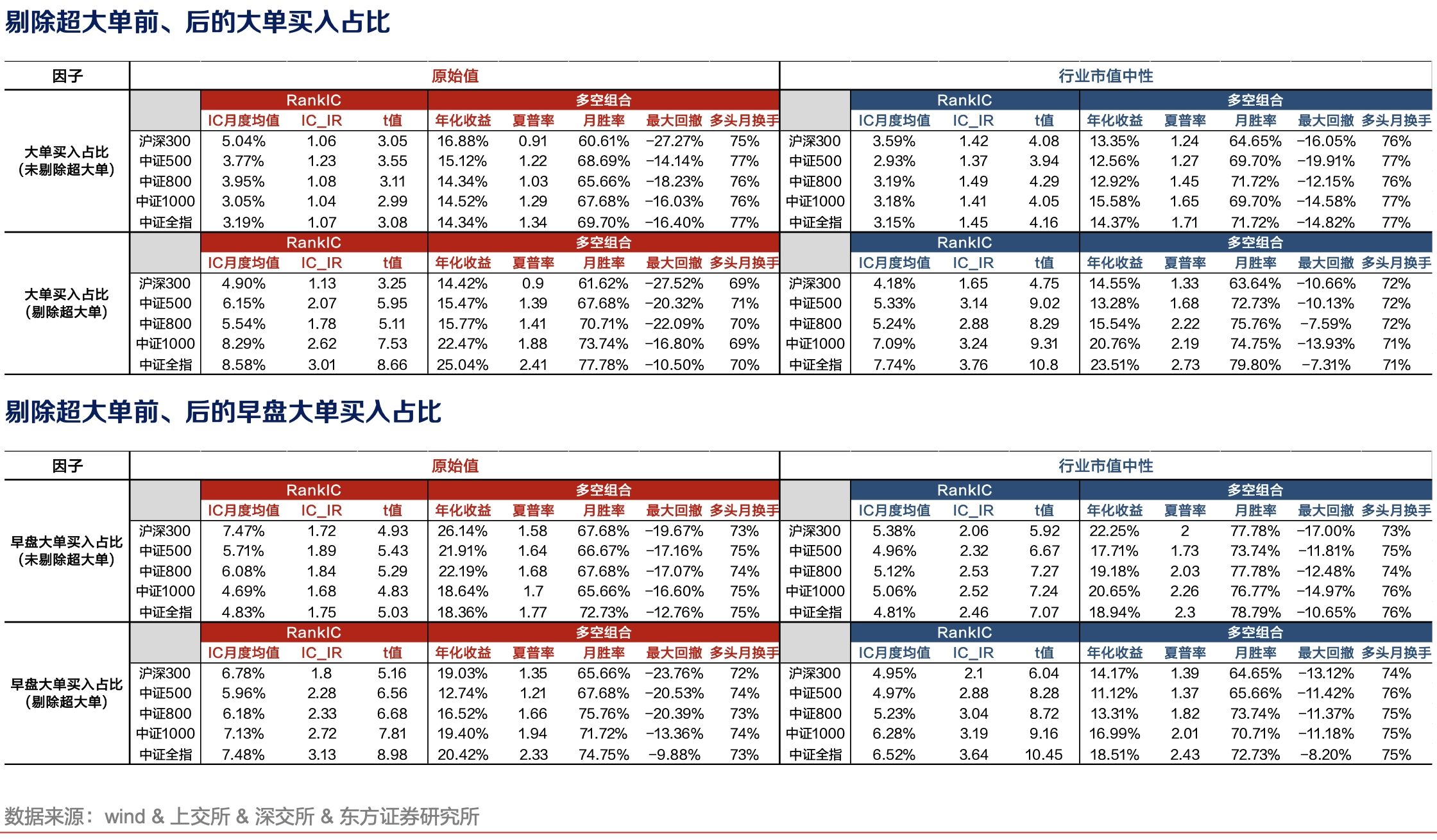
价格-资金流交互作用
与量价关系类似,资金流与价格的关系也值得探究。华安证券聚焦 “个股涨跌幅对资金流变动的敏感程度”,为刻画这个特征,具体计算步骤如下:
- 计算个股的日涨跌幅
- 计算个股层面资金流向的日变化率(5MAD 截面缩尾处理)
- 对每只个股计算过去20个交易日内日涨跌幅相对资金流日变化率的Beta(OLS回归)。不同类别资金流、交易方向以及资金单位下的因子在全市场中均具备显著的负向选股能力,即,涨跌幅对资金流变动不敏感的个股相对较为敏感的股票有超额收益。
开源证券提出 “散户羊群效应”,其计算方式为:当前交易日日内收益率与下个交易日早盘小单净流入之间的秩相关系数。该因子意图刻画散户对昨日高收益股票的追随效应。
总结
囿于因子计算的复杂度与因子发掘方向的不确定性,基于逐笔成交数据的资金流因子研究相对冷清,目前已公开发表的因子零零碎碎,效果也平平。但我个人对这一方向的判断是相对蓝海,只是要挖掘出与传统方向类似效果的因子,还需对微观结构的深入数据分析以及金融理论创新。另外,资金流特征与其他因子的交互作用是一个重要的探索方向。如,开源证券团队使用大小单占比对反转因子进行“切割”,国金证券用小单数据加强遗憾规避因子。“资金流+X”的范式应当能普遍应用于行为偏差导致的错误定价挖掘。
基于逐笔成交数据的股市资金流因子——雄关漫道真如铁