
2023第一阶段量化工作总结与展望
The unexamined life is not worth living.
本文首先介绍实施alpha策略缘起,回顾2023下半年第一阶段的策略研发工作,计划第二阶段任务,最后展望第三阶段。
因子投资
关于理想信念
对智人最好的描述是,他是会讲故事的动物
——尤瓦尔·赫拉利
人生需要理想信念。 250万年前,人类的祖先和其他动物一样生活在地球上,并无差异。直至7万年前,人类的智力才大幅的提高,成为世界统治者。在这次突变中,人类有了用语言进行抽象思维的能力。人类社会由各种抽象概念构成:国家、公司、组织等概念并非实体,而是根植于所有人心中的信念,这些概念组织起各种大规模协作,带领人类征服蛮荒世界,建立现代文明。这种信念如此重要,又如此匮乏——各种社会组织都会宣传自己的崇高的价值观和宏伟愿景,但鲜有人相信。这种匮乏本质上是真相与谎言的割裂:如果真相是法律和社会制度在保障国家机器的运转,就不能要求人们相信“X国梦”;如果公司存在的目的是最大化股东利益,手段是雇佣劳动,那员工就不能既是人力资源又被教导是“公司的主人”。当我每天的工作纯粹由月薪驱动,而无法相信手头工作的长期影响,我不仅感到这种工作状态效率较低,甚至是对有限生命的一种浪费。
不可否认的是,崇高理想是切实存在的。如果没有非凡的理想,就没有非凡的成就。“砍头不要紧,只要主义真。”人甚至愿意献出生命,以促成最终愿景的实现,哪怕自己看不到,甚至永远没有实现的那一天。某一种理想信念要被人信奉,有两个必要条件,一是足够美好,令人向往;而是足够真实,使人能够坚定不移地执行。
量化交易=自动赚钱? 从很早开始,量化交易的想法就吸引着我,“程序帮人自动赚钱”的愿景确实足够美好——但不真实,会写程序的人很多,但没有思想指引,少有人能相信自己的程序会赚钱。毕竟“回测猛如虎,实盘亏成狗”才是人生常态,无论在样本内收益多么优秀,实际性能一定大打折扣,甚至惨不忍睹。背后的原因是,所谓的“优秀策略”大概率是有多重测试(multi-testing)导致的假阳性,或者说是对历史数据的过度挖掘,样本外没有预测能力(回测过拟合)。因此,尽管很早就接触了量化平台,看见许多量化策略,但我始终无法笃行。我以回测过拟合作为本科毕设选题,并在以下两篇文章中进行了分享:
理论
转机在于2022年中读到石川博士《因子投资》一书,该书第一次将因子投资的理论及实践系统性地引入了中文世界。而此前其他介绍量化交易的中文书籍,不客气地说,都是些边角料。毫不夸张地说,我初读时大受震撼,震惊于量化投资可以有这么科学、系统的理论指导,之后时常翻读用于参考,每每能给予精神力量。
多因子模型是解释资产截面预期收益率的相对真理。 多因子理论认为,不同资产在某一时点的预期收益率取决于其对不同因子的暴露。
$$ \mathbb E(R_i^e) = \alpha_i + \beta_i \lambda $$
其中\(\beta_i\)是资产对因子的暴露,可以用公司特征代替,如用公司市值大小的对数作为对市值因子的暴露。\(\lambda\)表示因子收益率,\(\alpha\)则是预期收益中模型无法解释的部分,因此多因子策略也被称为Alpha策略。多因子模型至少有三大优势:
- 绕过对资产收益的时序预测。 通过量化精准预测资产未来走势进行择时,低买高卖,在日度、周度频率下基本是不可能完成的任务,市场过于复杂,而样本量远远不足。而因子模型中,专注于解释不同资产间相对收益,理论上可以通过多空对冲获取与市场无关的超额收益。
- 缓解多重测试影响。 基于人工规则的策略在回测中往往只进行有限次操作,很容易陷入过拟合。而因子模型中假设各资产独立,解释因子需要对所有时点的所有样本进行解释,如在A股中每年有100多万个样本,虚假发现很难通过显著性检验。
- 高度可拓展性。 为了更好地分析市场,向多因子模型中添加新的变量是常见操作,因子收益的来源是风险溢价或行为偏差。为了提高预测性能,将线性模型替换为非线性模型也是可以的。
以经典的Fama-French三因子模型为例,
$$ \mathbb E(R_i^e) = \alpha_i + b_m \cdot (R_m - R_f)+ b_s \cdot SMB + b_v \cdot HML $$
所有股票收益率由市场因子、市值因子SMB、价值因子HML所解释——这与人们的直观感受是一致的——市场整体走势会影响个股走势,相似市值、相似估值股票在同一时期也会有更类似的表现。因子投资的践行者如何获取超额收益呢?首先是将投资组合暴露于定价因子,享受因子溢价。如,根据FF三因子模型,给予小市值、低估值股票更大的权重。另一方面,更进取的收益来源是发掘私有的Alpha因子。市场能被若干个变量完全解释显然有悖直觉,大量发表在顶刊上的实证结果也表明,多因子模型具有很大的不确定性,且因子的稀疏性假设不成立。可以说,实证资产定价已步入因子的高维数时代。
投资者无法在事前投资中应对高维数,这主要体现在他们使用较少的协变量(因子)作为估值的依据。一方面,由于一些变量的获取成本很高,投资者需要在该变量带来的预测好处和其成本之间权衡。另一方面,有限理性中的有限注意力机制也为投资者对简约性的渴望提供了微观基础。这两方面作用合力导致投资者在为资产定价时使用过度稀疏的估值模型,导致资产没有被完全正确定价。
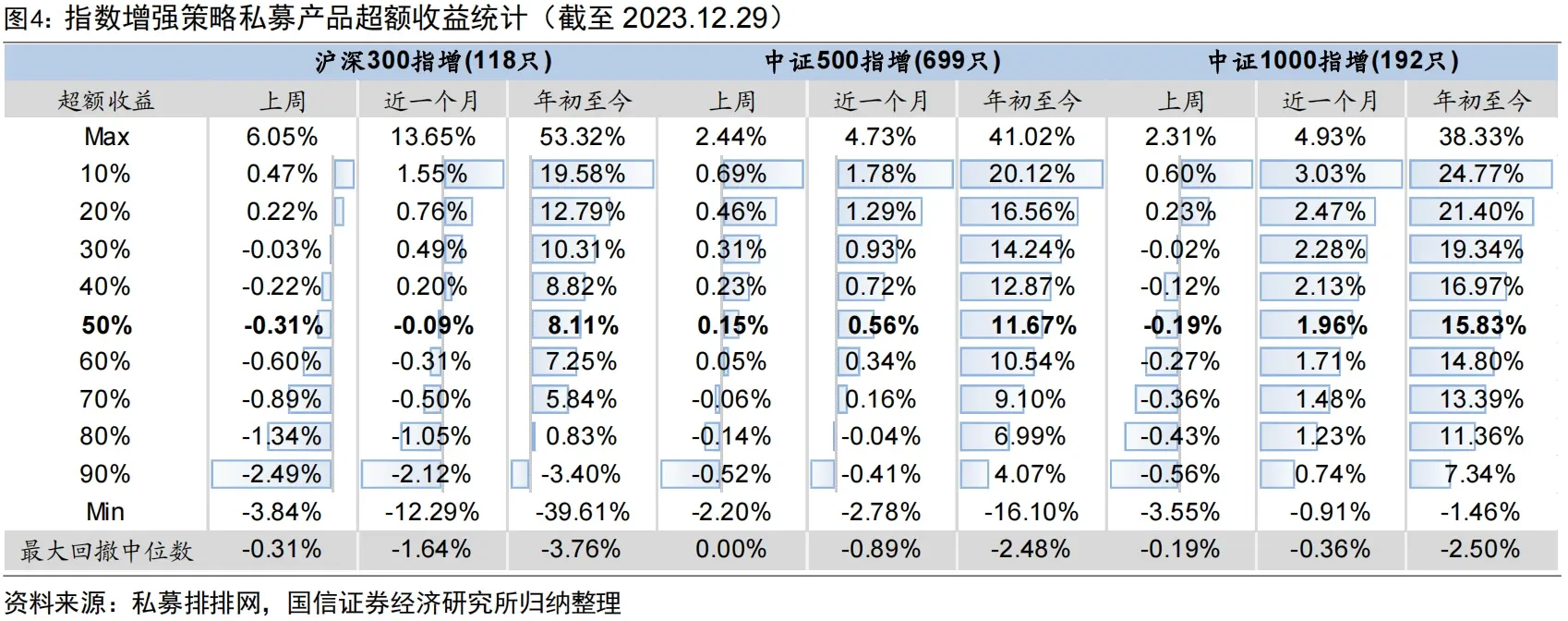
从产业现状来看,因子投资者通过付出工作量和发挥创造力挖掘因子,获取超额收益,是目前股票市场最主流的量化投资范式,在实践中也被证实可行。从2023年股票量化行业业绩数据观察到,第一,80%-90%的市场中性基金、指数增强基金可以实现正的超额收益,战胜市场是正确理论指导下的业界常态,而不依赖个人勇武。第二,在小市值指数域内量化策略表现更好,沪深300增强基金超额收益中位数8.11%,中证1000增强基金超额近乎翻倍达到15.83%,即使90%分位数超额也有7.83%,超额最大回撤仅2.5%。这是由于大公司股票已经被充分定价,套利空间较小,小市值企业由于投资者有限注意力导致错误定价更多。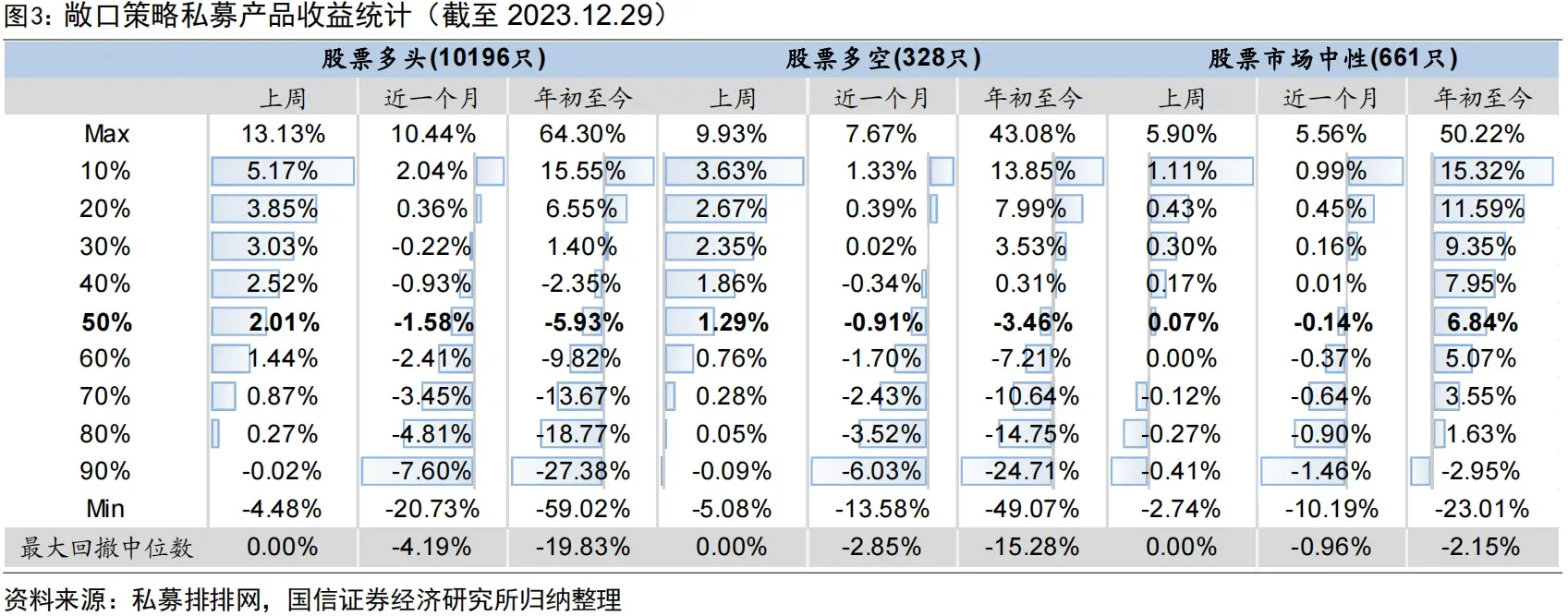
那么,一个显而易见的问题是,在巨鳄游弋的残酷市场中,个人做量化交易有获取超额收益的生存空间吗?从宏观上说,私有因子的发现和套利需要付出成本,并且边际效益递减,出于最大化利润率的现实考量,没有一个组织会赚走行业中的每一分钱。正如世界上存在巨型商超,也存在小型便利店,存在几万人的软件公司,也存在独立开发者。如果因子模型确实是高维数的,那么不同体量的个体应当占据不同的生态位。从微观角度讲,量化交易的目的是用一个错误定价交易筹码,只要有更愚蠢(或是迫不得已)的交易对手存在,这件事就可以运转下去。
实践
上文从理论角度解释了因子投资的信仰来源,本节讨论一个Alpha策略的具体实施路径。
Alpha策略=数据+因子挖掘+收益率模型+风险模型+组合优化+交易算法
一个完整的alpha策略首先依赖数据计算因子(可以理解为特征),用收益率模型预测收益,风险模型预测协方差矩阵,组合优化阶段综合两者最大化风险调整后收益。策略执行还需要交易算法优化交易成本。在考虑数据可得性、市场发展阶段和投资者强弱后,我判断A股和虚拟币市场是有利可图的。
在策略构建上,理查德·格林诺德(Richard Grinold)和罗纳德·卡恩(Ronald Kahn)提出的主动管理的基本法则表明,主动投资经理(或等效的量化模型)的表现取决于投资技能的质量以及投资机会数量。这一法则可以用数学方式表达为:
$$\text{IR} = \text{IC} \times \sqrt{\text{BR}},$$
其中:
- \(\text{IR}\) 表示信息比率,衡量了主动管理的效果;
- \(\text{IC}\) 表示信息系数,即模型对未来收益的预测准确性;
- \(\text{BR}\) 表示投资机会的频率与观察时间窗口之比。
这一公式强调了主动管理的关键在于投资技能的质量和投资机会的频率。如果一个投资经理能够更准确地预测未来收益(更高的信息系数),并且有更多的投资机会,那么其主动管理的效果将更好。机构投资者由于需求较高策略容量,通常无法做到高频换手,且只能在有限的选股范围、权重范围中进行组合优化以满足风控要求。而我计划在A股实施一个短周期、广域、低约束、小容量的alpha策略,具体阶段如下:
- 第一阶段(2023.9-2024.1,已完成)
- 数据:日频量价数据、逐笔成交数据
- 硬件:存储、算力
- 软件:因子计算、检验、优化框架
- 因子:日频、高频量价因子
- 第二阶段
- 收益率预测模型
- 风险模型
- 组合优化
- 数据:基本面数据
- 因子:基本面因子、行为金融学因子
- 第三阶段
- 程序化交易
- 交易成本优化
- 自动化AI与因子挖掘
- 另类数据与另类因子
整体流程分为因子挖掘、组合构建以及程序化交易。
第一阶段搭建因子投研框架,编写量价因子作为因子库主体,实现原始数据到因子库的计算。
第二阶段在因子库中添加基本面因子辅助模型决策,实现收益率模型与风险模型,基于预测构建投资组合,进行回测和实时监控。
第三阶段实现策略的程序化交易,优化交易成本,引入另类数据与另类因子、自动化AI。
一阶段回顾
硬件与数据准备
最先准备的是量价数据和存储、处理数据的计算机硬件。低频数据获取自Tushare。逐笔成交数据从数据商购买,每天近一亿条撮合成交记录,每年约数百亿条,未压缩时占用约1TB存储空间。原始数据处理后的衍生数据用函数形式导出,大部分在函数调用层面做磁盘缓存。硬件有一台文件服务器*1+计算节点*1, 主要配置
- cpu: 13900kf
- ram: 128 GB ddr4
- disk: 4TB ssd*2 raid0
- disk: 16TB hdd*2,up to *5
因子挖掘框架
高性能DataFrame 硬件规模的提升是有限的,软件效率则容易获取十倍百倍的提升。因子投资流程非常适合dataframe的数据结构,目前我的整个因子投研框架是基于Polars库搭建的,作为一个2020年诞生的年轻DataFrame库,polars保持易用性的同时,达到了一流的性能水平,革除了pandas的诸多弊病。其主要特点包括:
- 高效:Polars是从头开始设计的,紧密接近底层机器,并且没有外部依赖。
- 易用:用户以预期的方式编写查询。Polars在内部将通过其查询优化器确定最高效的执行方式。
- 离线处理:Polars通过其流式API支持离线数据转换,允许您在不要求所有数据同时存在于内存中的情况下处理结果。
- 并行处理:Polars通过在可用的CPU核心之间划分工作负载,充分利用了计算机的性能,无需任何额外的配置。
- 矢量化查询引擎:Polars使用Apache Arrow,一种列式数据格式,以矢量化方式处理查询,利用SIMD来优化CPU使用。
高频因子计算 框架实现了使用单节点cpu从快照数据、逐笔数据分钟级计算全时期天级别选股因子。出于充分利用数据局部性的考量,框架分天存储当日数据,第一阶段执行单日数据处理,聚合为天级别初步结果,第二阶段处理初步结果的日间关系。对于常用的中间结果,框架会自动缓存至硬盘。
因子超参数搜索 因子计算流程中很多通用/独有的超参数,如:聚合最近几天数据,要不要做行业中性化,阈值设置等等。人工搜索的效率是极低的,因此框架只定义超参数的范围,而不直接设置超参。基于Optuna框架,基于先进的参数搜索算法自动设置超参。
因子检验 计算RankIC、多头收益率、夏普比等指标进行因子检验,与主流方法并无二致。值得一题的是,引入了一种新的相关系数衡量分组收益率单调性。
量价因子
因子质量是策略盈利的核心,实现基于量价数据的技术因子也是第一阶段的主要任务。在最近数月内,我阅读并复现了数百篇金融工程研报和论文,基本涵盖了过去十年内国内公开发布的研究成果,入库量价因子150个左右。关于这些因子的总结也都已经整理并发布:
alpha因子,尤其是高频因子,各家都讳莫如深,不会有人把自己的盈利核心公开,因此只能自己从零开始实现。在复现这么多因子之后,最大的感触是由于学术研究的进展和市场经验,各类经典因子的思路大差不差,不是秘密,实现细节才决定最终效果好坏的主要因素,不足为外人道也。在整个过程中,因子表现整体符合预期,但可能由于预测周期变得较短,也有大量因子未能通过检验。对于思路、实现极为相似的因子,实现过程中尽可能进行整合和杂糅,选择较优的实现最终入库。此外尽管尝试过编写新因子,但效果大多不佳或是与已有因子相似度极高,因此这个阶段复现已有公开成果是效率最高方式,更多是在细节上进行优化。
二阶段计划
第二阶段的任务是,基于第一阶段建立的因子库,应用机器学习方法聚合多因子,构建投资组合,做绩效回测、样本外测试,并且实施例行更新与监控。同时,添加基本面等增量因子至因子库。
组合构建与回测
收益率模型与模型可解释性
收益率模型计划使用梯度提升树模型(LightGBM),其擅长处理中等样本量、低维稠密问题,能够自动学习因子间非线性关系,达到类似神经网络的性能。此外,决策树模型不需要处理极端值、缺失值、尺度放缩,操作便利。模型优化主要思路是,通过特征、标签变换,缓解不同时间样本不服从i.i.d.的问题。其次是用Optuna框架搜索合适的训练集长度、模型结构、损失函数等超参数。为了避免策略成为难以捉摸的黑盒,模型解释性同样重要,计划使用shap为全局和局部的模型解释提供支持。
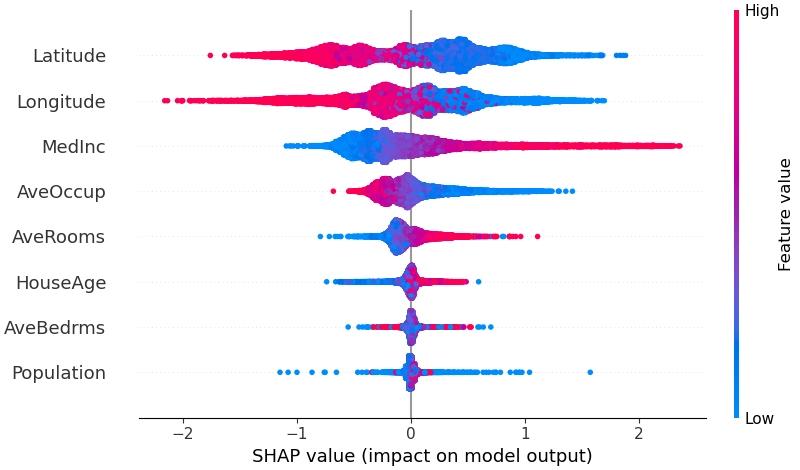
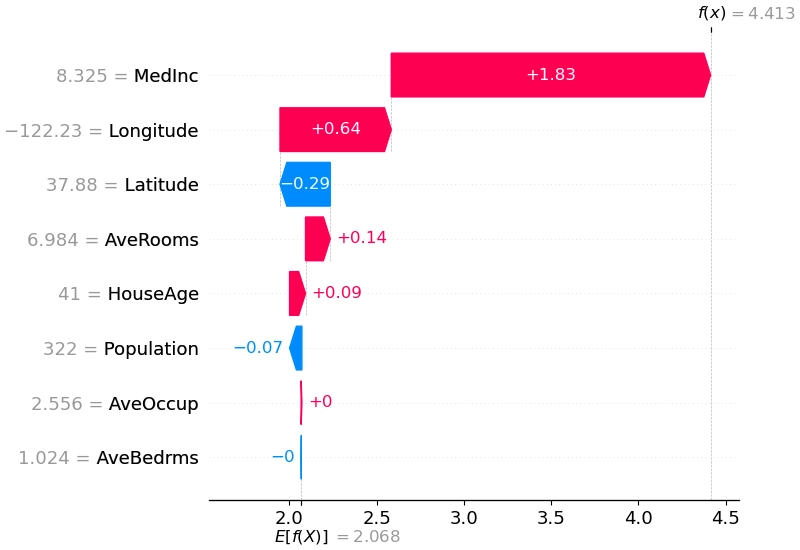
此前我寄希望于用排序学习方法(LambdaMART)直接处理收益率排序问题,但初步尝试后发现有严重过拟合的问题,先弃用。基于神经网络的复杂模型学术界研究相当充足,提升点主要在建模市场的时变特征和股票间关联关系,估计提升不大,也先搁置。
风险模型
目前主流的风险模型大约可以预测股票市场30%的协方差,将协方差信息引入组合构建有助于获取更高的夏普比。很多PM购买Barra风格因子(人工专家因子)作为风险模型,但首先,其性能在A股不是最优的,其次由于收益模型与风险模型特征不一致,组合优化时会低估部分风险,导致偏差。我计划直接使用机器学习方法搭建风险模型。基于矩阵分解的PCA方法是挖掘隐式因子的常用基线,不过其在样本外表现并不算好。2021年微软提出的Deep Risk Model(DRM)通过设计损失函数,首次将风险因子挖掘规范化为一个监督学习问题,实验也取得不错的效果。
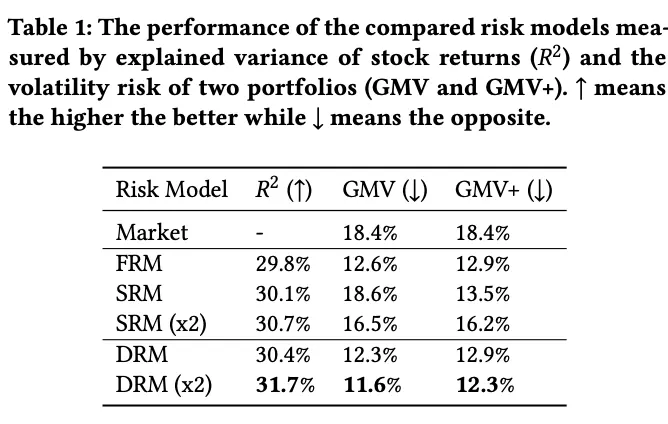
组合构建
在得到收益率预测\(\mu\)和协方差矩阵预测\(\Sigma\)后,还需要设定目标函数和约束条件,求解具体权重。最经典的目标函数是均值-方差优化:
$$ \max_w {\mu w - \frac{\zeta}{2} w'\Sigma w } $$
理论上,对于给定的风险等级,该组合能获得最高的预期收益。
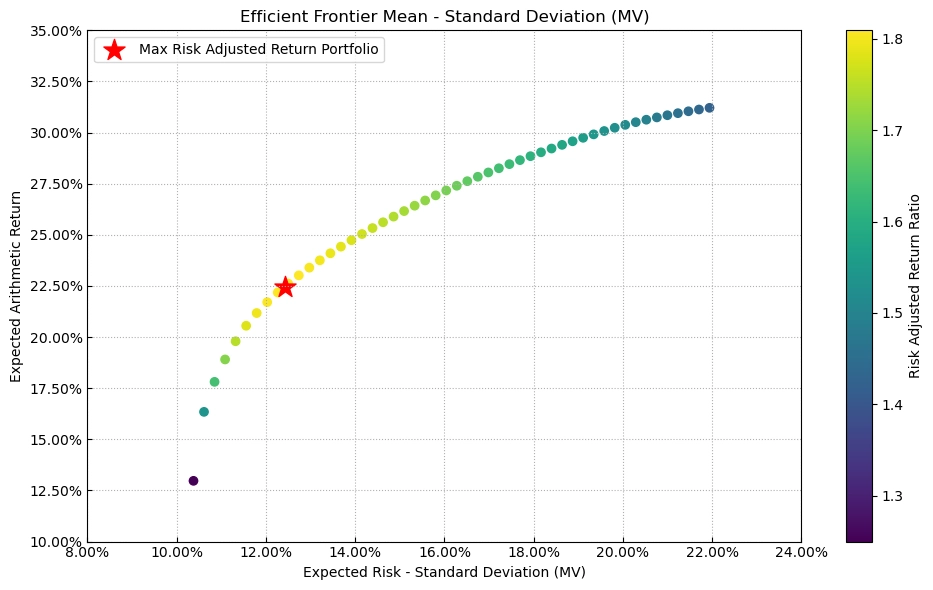
目标函数确定后,还需要添加约束,使得组合切实可行。常见的约束有
- 权重总和为1
- 行业/个股权重上限
- 换手率限制
- 是否允许做空
- 持仓数量约束
- 跟踪误差约束(指数增强策略)
在此不做一一列举。
回测与监控
上述步骤完成后,便能从原始数据得到一个具体的投资组合。接着通过样本内/样本外的回测,以及实时预测性能监控,评估策略性能。
实时监控会以web可视化面板的形式存在,初步计划采用metabase,涵盖下述层级:
- 重要因子监控
- 收益率/风险模型误差
- 投资组合PnL
因子挖掘
在第二阶段,因子挖掘方面的工作也会继续,主要有以下三个方面,
基本面因子 虽然基本面因子难以预测股价短期走势,但希望引入相对可靠的财务数据辅助模型决策。例如《因子投资》中介绍的基本面锚定反转因子,取基本面较好的前期输家作为多头组合,收益率远超原始反转因子。在输入基本面因子后,收益率模型应当能自动学习因子交互作用。
行为金融因子 第一阶段的量价因子研究更多是从数据出发,有这样的数据和计算能力>>写这样的因子>>效果不错>>入库。从行为金融学理论出发,是因子研究的另一条路径。如,国金证券提出的“遗憾规避因子”:投资者在收盘价低于其当日买入成本价时会更倾向于继续持有,且高于收盘价买入的成交量占比越高、相较于收盘价的价格偏离越大,股票面临更小的卖出压力,进而产生更高的预期收益;反之,投资者在收盘价高于当日卖出价时更倾向于坚持之前判断不再买回,且低于收盘价卖出的成交量占比越大、相较于收盘价的价格偏离越大,股票面临的买入动力越弱,进而产生更低的预期收益。
补充量价因子 对已有量价因子查漏补缺 1. 阅读可靠券商团队的其他研报 2.遍历《2023因子日历》《2024因子日历》
三阶段展望
程序化交易与交易算法
第三阶段主要任务是策略的实盘运行。首先需要实现程序化交易,实现方式是使用qmt。在执行买入/卖出指令时,实现聪明的交易算法减少冲击成本,优化交易成本也是非常重要的。经典交易算法有如TWAP、VWAP,前沿算法如多智能体强化学习甚至能把交易变得赚钱(存疑)。无论如何,对于这样一个中高频换仓的策略来说,程序化交易算法的精细化实现决定了因子模型的理论收益能否化为现实。
自动化AI
在博文Quant4.0(二)自动化AI与量化投研中介绍了自动化因子挖掘,第三阶段也计划引入机器学习因子,如循环神经网络、频谱分析+决策树等方案。至于基于遗传算法的符号因子挖掘,由于消耗算力显著扩大,且因子绩效、解释性并无优势,不在计划之中。
另类因子挖掘
另类数据引入和另类因子挖掘永远是令人热血沸腾的:私有信息意味着交易优势。
美国时间 2018 年 10 月 25 日,困境中的特斯拉(Tesla)股票录得 9.14% 的大涨,只因为在前一个交易日盘后发布的 2018 Q3 财报大超华尔街预期。财报显示,爆款 Model 3 的产量在过去一个季度较之前几乎翻番,这无疑给了投资人注入了一剂强心针,也引得市场一片狂欢。
面对 Model 3 产量的大增以及 9+% 大涨反映出的市场信心,最高兴的人当属 Tesla 的掌门人 Elon Musk。然而,除了 Musk 之外,同样高兴的另一群人大概要数另类数据公司 Thasos 以及它的很多对冲基金客户们。因为在 Tesla 发布 Q3 财报之前,这群人恐怕早就凭借着信息优势预判到了这一点,并提前在二级市场布局了。
Thasos 是怎么做到的?
他们在一张在线地图上环绕 Tesla 位于 Fremont,California 的占地 370 英亩的工厂,创建了一个数字围栏,以隔离从 Tesla 工厂范围内发出的智能手机位置信号。Thasos 租赁了数不胜数的智能手机 APP 收集到的数万亿个地理坐标的数据库,并通过电脑程序密切监测从 Tesla 工厂中发出的手机信号。使用手机信号量进行估计,他们发现从 2018 年 6 月到 10 月,Tesla 工厂夜间轮班时间增加了 30%,意味着产能的提高。Thasos 将这个数据分享给了它的一些对冲基金客户。毫无疑问,这一数据发挥了巨大的作用。
——石川 《另类数据的前景和陷阱》
第三阶段的另类因子挖掘可以从以下方面展开(部分思路已经十分常见,但与量价因子计算方式不同,因此还是归为另类因子):
- 北向资金跟随策略
- 分析师预期
- 机构调研行为
- 事件策略->事件因子
- 相似动量效应
- 舆情分析/研报情感/管理层情感分析
- 股东数量
这部分工作量集中在获取另类数据、使用AI或其他方式对异质数据进行分析。已有研报显示另类数据的绝对IC并不高,但多样化的数据来源产出的因子可能会对策略有更高的增量贡献。
2023第一阶段量化工作总结与展望