万倍加速——高性能正态积分的终极方案附代码
在毫秒必争的衍生品定价与大规模风险回测中,传统的正态分布积分运算往往是代码毒瘤和性能瓶颈。本文将介绍一种完全向量化的数值算法,助你利用现代 CPU、GPU 甚至TPU 的并行能力突破卡点。

在毫秒必争的衍生品定价与大规模风险回测中,传统的正态分布积分运算往往是代码毒瘤和性能瓶颈。本文将介绍一种完全向量化的数值算法,助你利用现代 CPU、GPU 甚至TPU 的并行能力突破卡点。
在前文 《衡量序列相关性的三个指标》 中我们介绍了能够发现变量间非线性、非单调关联的Chatterjee相关系数。它形式简单,计算快速,尤其适用于筛选非线性机器学习的输入特征。然而,新的研究表明,对于部分非函数依赖情形它的检测效率存在不足。本文首先回顾并展开介绍 Chatterjee’s \(\xi\) 的具体原理和关键特性。最后介绍一种同样一致的、无需参数的独立性检验算法 \(\tau^*\) 作为替代方案。
电影产业作为典型的高不确定性市场,其票房表现对出品方的财务状况及市场估值具有直接影响。票房的 超预期程度 是衡量市场对电影接受度的关键指标,同时也是评估电影公司业绩的重要变量。然而,传统票房预测方法往往依赖静态的点估计模型,难以精准刻画票房随时间演化的动态特性,更难以量化票房超出市场预期的幅度及其不确定性,难以转化为可行的投资策略。
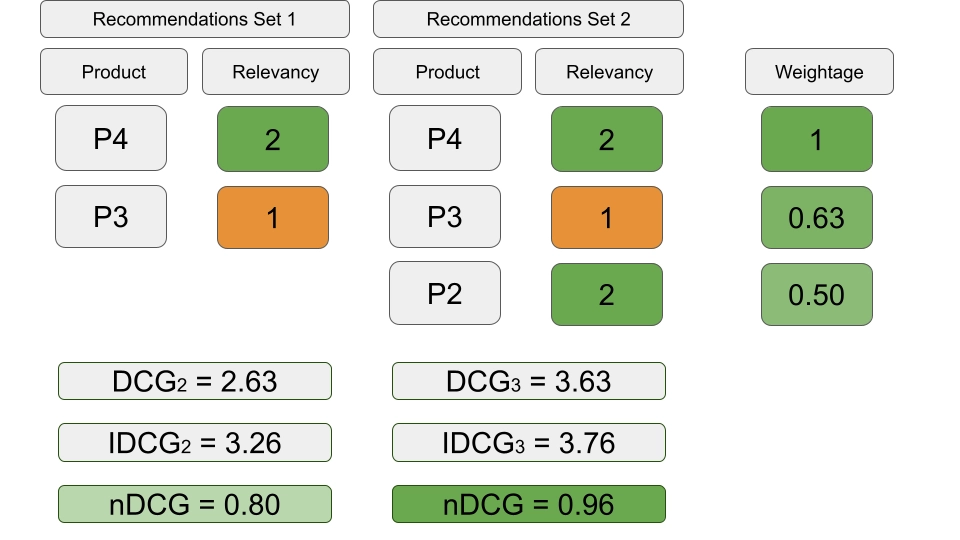
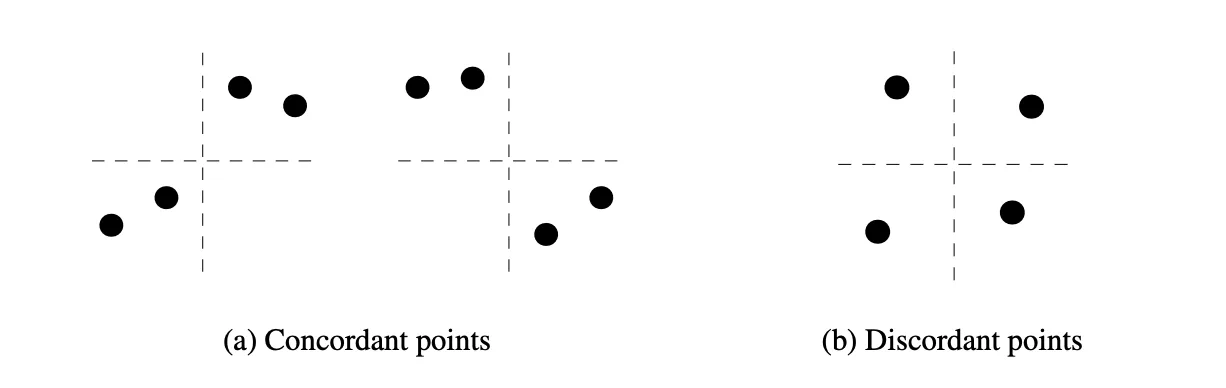
本文简要介绍了排序学习的背景、分类、性能度量,并归纳其发展历程中的几种经典算法。本文不追求深入每个技术细节,而是注重传递排序学习核心概念的直观理解,为LTR不同场景下的实际应用做铺垫。
Shaputa 是一种融合式特征选择技术,将 SHAP(SHapley Additive exPlanations)与 Boruta 的影子特征方法相结合。通过为每个特征构造随机基准线,再与模型生成的 SHAP 重要性进行对比,Shaputa 能在高维复杂数据中提供更加稳健、更加敏感于数据结构的特征选择结果,尤其适用于传统方法难以应对的非线性场景。
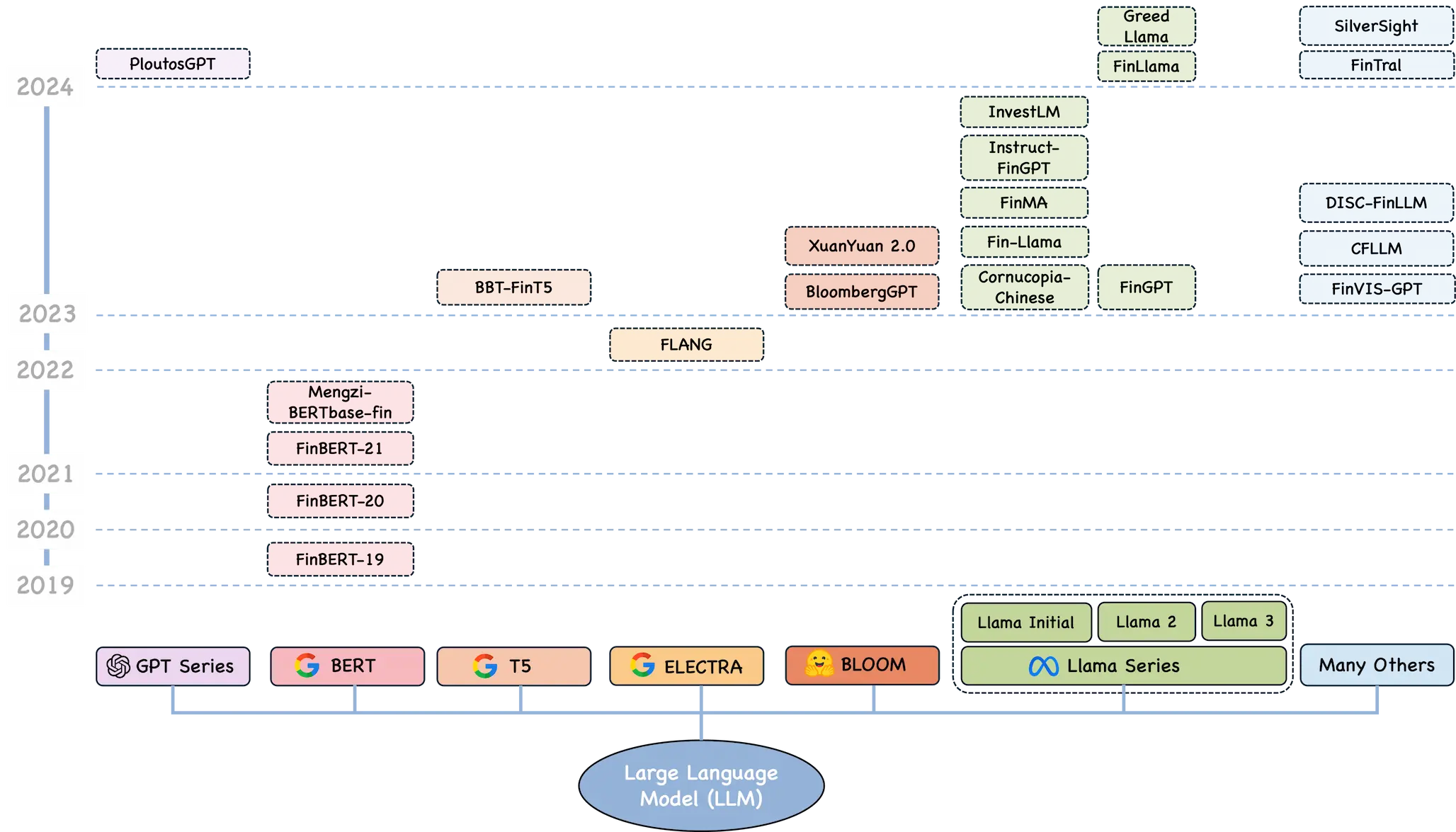
大语言模型(LLM)是2022年底ChatGPT横空出世以来,计算机技术中最炙手可热、日新月异的前沿领域。LLM已慢慢剥离单纯的工具属性,成为独立处理任务的智能载体。2024年,Qwen2、Llama3.1等千亿参数模型陆续发布,开源模型性能逐步接近闭源水平。作为量化研究人员,如何将大语言模型技术与金融应用相结合,提升投研水平,是必须思索的命题。本文首先参考李沐演讲分析LLM发展趋势与最佳实践,然后综述量化投资领域LLM的具体应用场景。

SHAP (SHapley Additive exPlanations)基于博弈论,是一种模型无关的机器学习解释方法,既能衡量单次预测结果中的特征贡献,也能聚合局部结果成为对模型的整体解释。SHAP方法在理论上有诸多优异性质,得益于大量工程优化,在实践中也有很强的可操作性,是XAI领域的重要方法。本文主要简介SHAP的基础理论,并给出应用示例。
本文介绍了三种度量变量相关性的指标:Pearson相关系数、Spearman相关系数和Chatterjee相关系数,最后一种可以简便地衡量非线性相关关系。
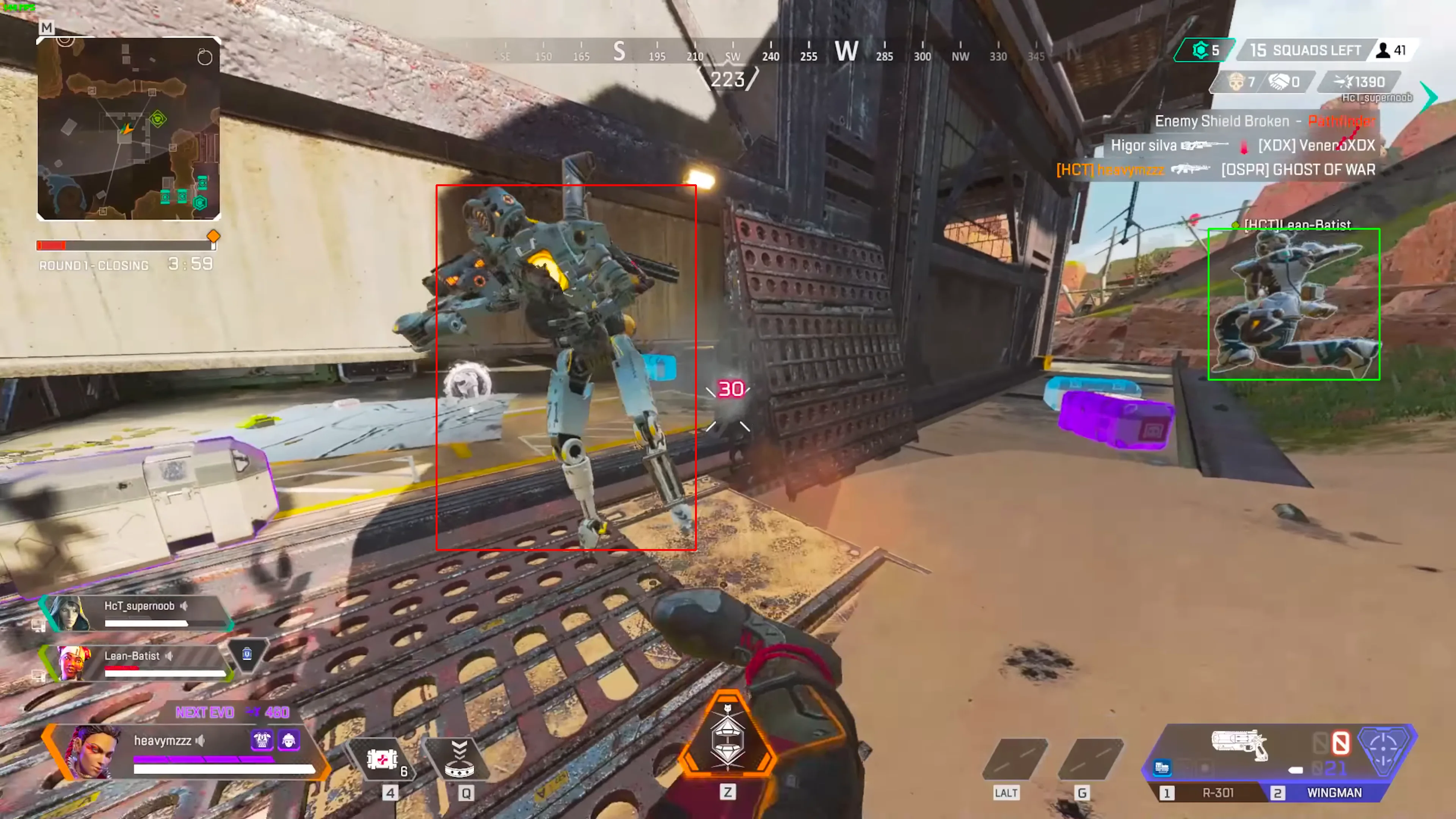
后羿(HOUYI) 定位于通用电子射击游戏瞄准辅助程序,目前支持的游戏是Apex Legends(以下简称apex)。其运行框架由识别-追踪二阶段构成,具体来说,先用目标检测算法识别出屏幕中敌人,再自动计算并校正准星位置。HOUYI的使命是用计算机技术对抗电子射击游戏对人的异化。

Don’t Panic
这个社会存在着——或者说将会存在——一个问题,那就是:大部分人在大部分时间产生数据,同时受数据支配,却对此一无所知。针对这一问题人类生产了大量文章,但其中绝大多数是从各种数学符号的组合入手的——这很奇怪,因为无知的并不是这些数学符号。
本文的写作目的是让您——哪怕从没听说过微积分——掌握进入大数据时代所需的一切知识。尽管显得冗长,并且包含许多虚假或者至少是不够准确的信息,但它在两个极其重要的方面超越了那些更加高深和老派的学术著作。
第一,它是完全免费的;第二,在它的开头以大而友善的字体写着“Don’t Panic”。其内容也使得读者略过繁难的数学公式,直接获取高层次的总体概念,笔者愿称之为Math-free。